
Abstract
This study uses a matching method to provide an estimate of the nativity wealth gap among older households in Europe. This approach does not require imposing any functional form on wealth and avoids validity-out-of-the-support assumptions; furthermore, it allows estimation not only of the mean of the wealth gap but also of its distribution for the common-support sub-population. The results show that on average there is a positive and significant wealth gap between natives and migrants. However, the average gap may be misleading as the distribution of the gap reveals that immigrant households in the upper part of the wealth distribution are better off, and those in the lower part of the wealth distribution are worse off, than comparable native households. A heterogeneity analysis shows the importance of origin, age at migration, and citizenship status in reducing the gap. Indeed, households who migrated within Europe, those who moved at younger ages rather than as adults, and those who are citizens of the destination country display a wealth gap that is consistently smaller over the entire distribution.
Similar content being viewed by others
1 Introduction
This study seeks to answer the question of how older migrants fare financially compared with natives. This is done by measuring the wealth gap between native and immigrant households across the wealth distribution. This is an important topic because wealth is a long-run indicator of well-being and gives insight into the economic integration of the foreign born. In addition, wealth is fundamental to income security for a non-negligible number of older (50+ years) immigrants who are approaching retirement. The most recent wave of the Survey of Health, Ageing and Retirement in Europe (SHARE Wave 6) shows that, in 2015, almost 10% of older interviewees were first-generation migrants. Given the surge of reforms aimed at reducing the generosity of social security systems all around Europe, it is vital to know whether such a large group is potentially at risk of poverty in retirement. Finally, appropriate policies depend on whether the wealth gap—if any—is driven by differences in observable characteristics. Despite its relevance, this is a largely understudied question.
While the literature has mainly pointed to the reasons why one should expect a positive wealth gap in favor of natives (e.g., earnings gaps, credit constraints, lack of destination country-specific information, institutional barriers, differences in social norms, limited access to social welfare programs), there are reasons to believe that some factors could dampen the gap and even lead to higher wealth for certain migrant households compared with natives. Freedom of movement, easier bureaucracy, and limited cultural or ethnic differences within Europe could, for example, foster allocative efficiency through better skill matching. Those who stay longer in the destination country may be a selected group of particularly well-integrated individuals, and those who migrated earlier may have had more time to integrate and adapt to the new country. However, a gap in favor of migrants may not be apparent if one looks only at the average or median gap, as has been the case in most previous studies. At the same time, the average gap could hide a much larger gap for certain migrant households. In general, the distribution of the gap along the wealth distribution is much more informative than a single statistic.
Another common limitation of previous literature is that it did not restrict wealth comparisons to households with comparable characteristics. Besides, in most cases, the decomposition methods used are based on linear relationships when, in fact, the wealth function is unknown and most likely highly non-linear. A noticeable exception is Barsky et al. (2002), who recognized the limits of the Blinder-Oaxaca decomposition and measured the portion of black–white wealth gap in the US explained by earnings using a non-parametric method, which did not require extrapolation outside the range of observed explanatory variables.
This study adds to the literature in several respects. Following Frölich (2007) and Ñopo (2008), a matching strategy is used to estimate the gap between native and migrant households (as well as mixed households) in Europe during the years 2006 to 2015 and to partition the gap into its explained (by observables) and unexplained parts. Second, the data at hand allow for the calculation of pension wealth in addition to real and financial wealth. Pension wealth is generally disregarded due to data limitations.Footnote 1 This represents a serious omission given that this study shows that pension wealth accounts for around half of the total wealth of older Europeans. Third, the decomposition method adopted does not require the specification of a functional form for wealth, thus avoiding misspecification errors. Fourth, this study goes beyond the average gap by estimating the distribution of the unexplained gap. The average gap may in fact be misleading, given that the wealth distribution is typically highly skewed. More importantly, the average would hide the presence of heterogeneity of the gap across the wealth distribution. Finally, the approach adopted restricts the comparison to individuals with comparable characteristics in both groups. Linear models, on the contrary, implicitly assume validity-out-of-the-support, because they do not take into account the differences in the support of the empirical distributions of individual characteristics.
Besides the methodological differences, this study separately analyzes households where both spouses are immigrants and households where only one of the spouses is an immigrant. Furthermore, given the heterogeneity of migration toward and within Europe, different groups of migrant households are separately analyzed, depending on their origin, age at migration, and citizenship status. It is important to underline, however, that this study does not try to answer whether immigrants are better off due to migration than stayers in the home country. This is an equally important question, which is left to future research.
This study finds that the average wealth gap delivers a very partial picture of the gap between natives and migrants. Even though the average gap is positive and significant, it hides a very interesting distribution, where immigrant households in the upper part of the wealth distribution are better off, and those in the lower part of the distribution are worse off, than comparable natives. Furthermore, the gap after matching is larger than the unconditional gap over most of the distribution. In the case of mixed households, even the average gap found after matching is larger than the unconditional gap.
Moreover, a heterogeneity analysis reveals that origin, age at migration, and citizenship are important determinants of the wealth gap. Households who migrated from within Europe have a lower relative gap than those who migrated from outside Europe. The same is even more true for those who migrated at young ages than for those who migrated as adults, as well as for those who hold the citizenship of the destination country.
The structure of the study is as follows: Section 2 discusses the theoretical background and summarizes previous literature on the measurement of the nativity wealth gap. Section 3 presents the data and some preliminary descriptive statistics. Section 4 discusses the drawbacks of previous methods used to measure outcome differences between two groups and introduces the propensity score matching method and its advantages over the Blinder-Oaxaca method. Section 5 presents the results and proposes a detailed decomposition analysis. Section 6 analyses the heterogeneity of the gap for different groups of migrants and Section 7 concludes.
2 Background and related literature
The migration literature has pointed to a number of reasons why one should expect migrants to be worse off than natives. Older families, in particular, may primarily count on three types of resources: social security income, pensions and private savings, and wealth (see Sevak and Schmidt 2014). For migrants, these resources may differ as a result of differences in inherited wealth, rates of return, or savings behavior, which in turn may depend on both the country of origin and destination country characteristics.
In terms of wages, an extensive literature shows that immigrants face a relative earnings gap at arrival. This tends to disappear over time, even if there is no agreement on the extent to which this reflects a gap in unobserved characteristics or on the speed of convergence (see Borjas 1994).Footnote 2 The lack of destination country-specific information and institutional barriers associated with language skills, ethnicity, or legal status could drive a wedge between native and foreign-born wealth (Cobb-Clark and Hildebrand 2006). Interestingly, Osili and Paulson (2004) show that the likelihood of financial market participation decreases with higher levels of ethnic concentration in the immigrant residence area. Osili and Paulson (2008) also find that immigrants from countries with more effective institutions are more likely to own stock in the US. McKernan et al. (2014) found that African Americans and Hispanics (both immigrant and non-immigrant) receive less private transfers in the form of large gifts and inheritances than whites. As financial literacy starts in the family, as pointed out by Lusardi and Mitchell (2014), by observing parents’ saving and investing habits or from directly receiving financial education, it may well be that financial literacy is also related to specific cultural or ethnic differences (see, for example, Haliassos et al. 2016).
Countries’ regulations covering immigrant welfare eligibility may also contribute to the wealth gap: limited access to social welfare programs could in fact induce immigrants to accumulate more resources to cope with financial difficulties (see Bauer et al. 2011). Related to this are the rules regulating pension coverage. If social security or pension rules require a minimum number of contribution years, some immigrants may not be able to meet eligibility criteria, and even when they do, depending on the pension system, they could receive lower benefits because of lower earnings or fewer contribution years.Footnote 3 However, depending on the redistributive nature of the pension system, immigrants could get higher replacement rates than natives (see Favreault and Nichols 2011).
As the vast majority of current evidence refers to the US, and mostly to black–white or Hispanic–white differences, theoretical discussions regarding immigrant–native differences in Europe are scarce. However—at least with regard to within-Europe migration—there could be some factors that dampen the emergence of a positive nativity wealth gap or even allow the emergence of a negative gap.
Freedom of movement of workers is one of the four fundamental pillars of economic integration in the European Union (EU) and has been a major goal of European integration since the 1950s. This required the lowering of administrative formalities and called for increased recognition of professional qualifications of other states. In turn, this entailed the abolition of any discrimination based on nationality between workers of the member states in regard to employment, remuneration, and other conditions of work and employment.Footnote 4 Besides, the risks and costs of migration typically grow with the geographic and cultural distance from the destination country, as information about distant labor markets is more difficult to obtain. For the majority of European countries, these costs should be fairly small.
The literature on the nativity wealth gap is small. In terms of wealth accumulation, Amuedo-Dorantes and Pozo (2002) look at the saving behavior of immigrants and natives in the US using data from the 1979 Youth Cohort of the National Longitudinal Surveys (NLSY79). They find that immigrants on average accumulate less wealth than comparable natives and that natives appear to carry out more precautionary savings than comparable immigrants, even if immigrants may engage in precautionary savings by remitting money to their home countries. With regard to European countries, Bauer and Sinning (2011) use data from the German Socio-Economic Panel (SOEP) and distinguish between permanent and temporary immigrants. They show that if remittances are treated as savings, migrants who intend to return to their home country save significantly more than comparable natives. Additionally, a decomposition analysis shows that most of the differences between permanent immigrants and natives and between permanent and temporary immigrants may be attributed to observable characteristics. De Arcangelis and Joxhe (2015) find similar results for the UK using data from the British Household Panel Survey. They show that temporary migrants have a propensity to save 26% higher than permanent migrants in the UK, and a decomposition analysis shows that migrants are more affected by observable socio-economic characteristics than natives.
A common finding in the literature is that immigrant households are less likely to be homeowners. Borjas (2002) finds that the national origin of immigrants and the residential location choices made by different immigrant groups are key variables in explaining the gap in homeownership. Constant et al. (2009) find that, in Germany, immigrants with a stronger commitment to the destination country are more likely to achieve homeownership for a given set of socio-economic and demographic characteristics. Sinning (2010) finds that the assimilation process in homeownership between native and immigrant households did not take place in Germany.
The closest papers to this one are those that study the relative wealth position of the foreign-born population. Cobb-Clark and Hildebrand (2006) analyze the net worth and portfolio choices of foreign-born individuals in the US using the Survey of Income and Program Participation (SIPP) data. They estimate a reduced form model of the determinants of net worth and find that the median wealth of the US-native couples is 2.5 times that of immigrant couples, and 3 times for singles. Sevak and Schmidt (2014) use the Health and Retirement Study (HRS) data linked with the restricted data from the Social Security Administration to compare retirement resources of immigrants and natives and find that immigrants have lower levels of Social Security benefits than natives, but higher levels of net worth when holding demographic characteristics constant. They observe heterogeneity in the estimated immigrant differentials that depends on the number of years in the US, with the most recent immigrants the least prepared for retirement. Bauer et al. (2011) find that in Germany and the US the wealth gap is explained by different educational and demographic characteristics, while, in Australia, immigrants do not translate their educational advantage into a wealth advantage. To the best of this author’s knowledge, there is no similar evidence on the relative wealth position of the foreign-born population in the entirety of Europe.
3 The Survey of Health, Ageing and Retirement in Europe
3.1 Data description
This study utilizes waves 2, 4, 5, and 6 of SHARE (Survey of Health, Ageing and Retirement in Europe),Footnote 5 which covers the period 2007 to 2015.Footnote 6 SHARE is a multidisciplinary and cross-national panel database of micro data on health, socio-economic status, and social and family networks of individuals from 20 European countries aged 50 or older. The richness of the information in SHARE is particularly useful for the purposes of this study and will allow both the construction of a comprehensive measure of wealth and the matching of households over a large set of characteristics. This is particularly useful given the econometric approach that will be used. SHARE also contains information on individuals’ country of birth, migration year, and citizenship.
Each wave of SHARE includes individuals who were already interviewed as well as new individuals. Thanks to these refreshment samples, younger age cohorts of the target population who were not age-eligible in the previous waves enter the sample. Besides, they allow compensating for the loss of observations in the longitudinal sample due to attrition across waves (see Stuck et al. 2018). The data are employed here as repeated cross-sections. Cross-sectional weights—used throughout the study—are computed separately by country to reproduce the size of the national target populations in each wave of the study, thus making the cross-sectional sample representative. Furthermore, clustered standard errors, which take into account the potential correlation of errors from measurements arising from the same individuals, are also always employed here.
A common issue of survey data is the presence of item non-response, which is normally particularly high for monetary variables. Ideally, one would use wealth data where the problem of item non-response is negligible or completely absent, but in surveys this is unfortunately not an option.Footnote 7
This raises a practical and a technical negative consequence. The former is that using only “complete cases” (that is, observations for which there are no missing values for any of the variables the researcher needs) would drastically reduce the sample size. More importantly, even if one could count on a sufficiently large number of non-missing observations, it is strongly advisable to use imputed values. The reason is that when missingness is non-random, as is most likely the case for monetary values, any estimate obtained using only complete observations would produce biased results (Little and Rubin 2014). Several studies (see Appendix Table 8 for details) show how the use of imputations of missing values reduces biases due to item non-response. For this reason, this study includes imputed data. Appendix Table8 discusses in detail why employing imputations is important and carefully describes the inference methods utilized in the study.
After merging waves 2, 4, 5, and 6 of SHARE, the initial sample consists of 150,560 households (220,235 interviewee). Some basic demographic variables as well as wealth variables are imputed; so, they do not contribute to the reduction of the sample size. Households with missing information on the non-imputed variables used in the matching procedure are dropped. In very few cases, country of birth could not be recovered, which led to the observation being dropped. Besides, only couples in which both partners are interviewed and with no missing information on future pension entitlementsFootnote 8 or any other non-imputed variables are kept. In fact, in this study, information on both spouses is always used, in contrast with previous literature where only variables referring to the head of the household were used. This is done first of all because defining the head of the household always involves a certain degree of subjectivity. Second, and more importantly, matching on the characteristics of both spouses considerably improves the quality of matching as it allows the distinction of male and female characteristics. Third, it seems particularly relevant to include the characteristics of both spouses for migrant and mixed households, given the relevance that characteristics such as the country of origin may have. Since in more than 50% of the cases single households consist of widowed individuals for whom information on the deceased spouse is not available, the analysis will concentrate on couple households. However, as single households have a high risk of poverty in old age, some results on single households are also provided. The sample selection leads to a final sample of 44,035 couple households and 35,130 single households.
Immigrants are defined as respondents who were born in a country different from the one where they reside at the time of the survey. Throughout the analysis, couple households are divided into the following three groups: those where both spouses are natives, those where one spouse is native and the other is an immigrant (mixed households), and those where both spouses have a migration history (immigrant households). This is done as mixed and migrant households may be different in a non-trivial way, and, thus, it is more reasonable to treat them separately. The sample consists of all couples where both spouses are interviewed and single households from 17 European countries.Footnote 9 The population with a migration background in the final sample consists of 1770 migrant couples, 3683 mixed couples, and 3746 single households. Table 2 shows the sample size by European region and household type.
The dataset contains information on a number of wealth items at the household level, the sum of which amounts to the overall (net) real and financial wealth of households. Specifically, households’ real assets are given by the sum of the value of main residence net of the mortgage on main residence, the value of real estate, the value of own businesses, and the value of cars. Households’ financial assets are given by the sum of the value of bank accounts, bond, stocks, and mutual funds, plus savings for long-term investments and net of financial liabilities. In turn, savings for long-term investments are given by the amounts in individual retirement accounts, the value of contractual savings for housing, and the face value of whole life policies.
In the final sample, the percentage of missing—and therefore imputed—values is lower than 13% for most wealth items (specifically, the value of real estate, owned businesses, cars, bond, stocks, mutual funds, mortgages, and liabilities). It is around 20% for the value of house and of savings for long-term investments and reaches 34% for the value of bank accounts. The frequency of missing values in net wealth between native and migrant or mixed households is not statistically different.
SHARE also contains information that can be used to obtain a measure of individuals’ pension wealth. Specifically, individuals are asked whether they receive any pension and, in the case of an affirmative answer, the after-taxes amount of the monthly benefit is asked. Individuals are also asked whether they are eligible for any pension, and, in this case, they are asked about the date they expect to collect said pension and their expected replacement rate.Footnote 10 Following Alessie et al. (2013), a pension wealth measure is calculated for those who already receive a pension assuming constant real pension benefits. For those who will be eligible for a pension but are not yet receiving it, the expected replacement rate multiplied by current wage and the expected age of retirement are used to obtain the pension wealth measure. When expected retirement age or expected replacement rate are missing, country statutory retirement age and replacement rates for the average worker are used.Footnote 11 Pension wealth is defined as the present value of the future flow of pension benefits, Bτ, and is calculated assuming a 1% annual real interest rate, r, and a maximum age, L = 110:
where, R is retirement age, and all future incomes are weighted by country-, year-, and gender-specific survival rates obtained from the Human Mortality Database.Footnote 12
3.2 Descriptive statistics
In the final sample, 8.4% of the married couple households are mixed and 4% are immigrant. Figure 1 shows the frequency distribution of immigrants by number of years since migration. It is clear that the vast majority of foreign-born individuals have been living in their destination country since they were very young. While the median number of years in the US found in the HRS data is 36 (see Sevak and Schmidt 2014), interestingly the corresponding median in SHARE is 45, meaning either that individuals migrate to European countries at a much younger age or that individuals who have been living longer in Europe have a lower probability to re-emigrate with respect to immigrants in the US or both.

Distribution of immigrants by number of years since migration. Notes: N = 6950
It is important at this point to note that the migration literature tends to distinguish between temporary and permanent migrants. These two categories of migrants display different behaviors in terms of, for example, savings behavior (see Bauer and Sinning 2011 and De Arcangelis and Joxhe 2015), working hours (Kahanec and Shields 2013), and economic assimilation, in general (Dustmann 2000). As migration usually happens at younger ages and re-emigration occurs within the first years in the destination country,Footnote 13 it can be argued that this study, by using a sample of individuals older than 50, studies a group of permanent migrants. This facilitates the interpretation of wealth comparisons between natives and migrants since there is no need to correct for the presence of temporary migrants; besides, the relative wealth position of permanent migrants may be more relevant for destination countries’ policies directed toward older migrants.
Figure 2 shows the proportion of foreign-born individuals by their area of origin and of residency. For the sake of convenience, countries of origin are aggregated into seven main regions (Africa, Central and Northern Europe, Eastern Europe, Southern Europe, Russia, and former USSR countries, Arabic countries, and “Rest,” a residual category which includes migrants from any other region) and European destination countries are aggregated into four macro-areas (Northern, Central, Southern, and Eastern Europe).Footnote 14 This picture clearly shows a large variation in terms of diversity of the migrant population in Europe. The vast majority of immigrants in Northern Europe come from other Northern countries or from Central Europe, while almost all immigrants in Eastern Europe come from other eastern countries or from Russia and former USSR countries.Footnote 15 The immigration pattern in Central Europe is instead more equally spread among origin regions, while Southern Europe registers the biggest presence of immigrants from Africa and from the “rest” of the regions (mainly Asia, the US, Latin America, and Australia).

Proportion of immigrants by origin and destination. Notes: Northern Europe includes Sweden and Denmark; Central Europe includes Austria, Germany, the Netherlands, France, Switzerland, Belgium, Ireland, and Luxembourg; Southern Europe includes Spain, Italy, and Greece; Eastern Europe includes Czech Republic, Poland, Slovenia, and Estonia. N = 7184. Observations are weighted using cross-sectional weights
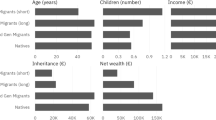
Figure 3 shows the proportion of households owning the main types of assets by European region and household type. In general, there is a stable pattern of lower ownership for immigrants than for natives, with mixed households ranking in between. An exception is savings for long-term investment in Southern Europe, where the ownership proportion is higher for immigrants than for natives or mixed couple households. Ownership of financial investments shows a very different distribution across the four European regions: it exceeds 50% in Northern Europe for all household types (48% for immigrant households), but it does not reach even 10% in Eastern Europe, while savings for long-term investment are especially low in Southern Europe.

Assets ownership. (a) House, (b) cars, (c) bank accounts, (d) bond, stocks, mutual funds, and (e) savings for long-term investments. Notes: Northern Europe includes Sweden and Denmark; Central Europe includes Austria, Germany, the Netherlands, France, Switzerland, Belgium, Ireland, and Luxembourg; Southern Europe includes Spain, Italy, and Greece; Eastern Europe includes Czech Republic, Poland, Slovenia, and Estonia. Native households: N = 38,582; migrant households: N = 1770; mixed households: N = 3683. Observations are weighted using cross-sectional weights. Standard errors are clustered on the individual
Table 1 shows the mean and median total net wealthFootnote 16 of couples, by European region and household type. As expected, median wealth is always lower than the mean due to the right-skewed distribution of wealth. Similar to ownership rates, the level of wealth is higher for natives than for immigrants, while mixed households rank in between. Eastern countries appear to be an exception, with rather similar wealth levels among the three household types.Footnote 17 Wealth levels are highest in Northern Europe and lowest in Eastern Europe for all household types with the exception of immigrant households in Southern Europe, which exhibit the lowest levels of wealth.
Figure 4 displays pension, financial, and real wealth as proportions of total wealth, by European region and household type. A striking feature is that on average almost half of total wealth consists of pension wealth, confirming the fact that ignoring it is a serious omission. Real wealth amounts on average to 45% of the total, and the remaining 8% is composed of financial wealth. The wealth composition pattern of different households is relatively similar in Northern and Central Europe, which are also the regions where the share of financial wealth is bigger and that of real wealth smaller. The share of real wealth is instead the highest in Southern Europe.

Wealth components (%), by region and household type. Notes: Northern Europe includes Sweden and Denmark; Central Europe includes Austria, Germany, the Netherlands, France, Switzerland, Belgium, Ireland, and Luxembourg; Southern Europe includes Spain, Italy, and Greece; Eastern Europe includes Czech Republic, Poland, Slovenia, and Estonia. Native households: N = 38,582; migrant households: N = 1770; mixed households: N = 3683. Observations are weighted using cross-sectional weights. Standard errors are clustered on the individual
Table 2 describes some socio-demographic characteristics of natives and immigrant households. What stands out for immigrant households is the considerably lower probability of having ever received an inheritanceFootnote 18 and the much higher probability of being unemployed for immigrant males. In general, however, it is difficult to find a consistent pattern that distinguishes mixed and immigrant households from natives. This is not surprising, since mean characteristics hide the heterogeneity of migrants deriving, for example, from their different regions of origin.
4 Econometric strategy
4.1 Decomposition methods
The standard approach to measure an outcome gap between two groups is the Blinder-Oaxaca (B-O) decomposition.Footnote 19 This method requires a linear regression estimation of a variable of interest for both groups and allows the decomposition of the average gap into two components: one attributable to differences in the average characteristics of individual and the other to different returns to these characteristics.Footnote 20
Two separate wealth equations are estimated for native and immigrants (or mixed) households:
where, Xk are factors hypothesized to determine wealth, N stands for native households, F for immigrant households, and h for index households. The average wealth gap can then be written as:
The first term, \( {\widehat{\Delta }}_X^{\mu }, \) represents differences in average characteristics between natives and immigrants, while the second term, \( {\widehat{\Delta }}_S^{\mu } \), represents differences in average returns to the household characteristics. \( {\beta}_N{\overline{X}}_F \) may be thought as the wealth level immigrant households would have if they had the same returns as natives or the wealth level native households would have if they had the same characteristics as immigrants.
This approach presents several issues. First, it only allows one to estimate the average gap, which may be misleading given that the wealth distribution is typically highly skewed. More importantly, the average would hide the presence of heterogeneity of the gap across the wealth distribution. Second, the B-O decomposition assumes a linear relationship between explanatory and outcome variables. In the case of wealth, this amounts to imposing the unlikely assumption of additive separability between income and demographic characteristics.Footnote 21 Third, the B-O decomposition is potentially subject to misspecification due to differences in the supports of the empirical distributions of individual characteristics for the two groups of individuals analyzed (see Mizala et al. 2011), and it implicitly assumes validity-out-of-the-support (see Ñopo 2008). It does not in fact restrict the comparison to individuals with comparable characteristics, and it is also possible that comparable individuals do not exist at all in some parts of the supports.
Following the work of Frölich (2007) and Ñopo (2008), matching can be used as a non-parametric alternative to B-O decomposition. Specifically, Propensity Score Matching (PSM) is a technique used to identify a control group with the same distribution of covariates as a treatment group and, as demonstrated by Frölich (2007), it can be used in applications other than treatment evaluation. It differs from the parametric approach in that it does not require estimation of a conditional expected wealth function, thus avoiding the errors that could arise from misspecification of the functional form.Footnote 22 Besides, the (adjusted) mean gap is simulated only for the common support sub-population. Finally, it allows one to estimate what the entire distribution of an outcome variable, Y, would be in a particular population if its covariates, X, were distributed as in another population.
In this study, PSM is thus used to identify native households which display the same characteristics as immigrant or mixed households, and then compare their wealth levels. The PSM estimator is therefore the mean difference in wealth over the common support, weighted by the propensity score distribution of immigrant or mixed households. If mg(x) ≡ E[Y|X = x, G = g] denotes the mean wealth and fg(x) the distribution of X among households of type g, and S denotes the common support of fF and fN, then the counterfactual wealth can be simulated and the nativity wealth gap can be again decomposed into an explained and an unexplained part:
where the first term represents the part of the gap that can be attributed to differences in the distribution of characteristics between natives and immigrants, while the second part is due to differences in returns to these characteristics. Furthermore, in order to know how the gap evolves in different parts of the wealth distribution, the distribution function of natives, FW ∣ g = N(a), can be adjusted for differences in covariates between natives and immigrants. The adjusted distribution function for natives can be written as:
This can be estimated using matching, which can be performed on the propensity score instead of the covariates X as proven by Frölich (2007), and the adjusted quantiles can be obtained by inverting the adjusted distribution function. At any percentile, the horizontal distance between the adjusted distribution and the immigrant distribution is a measure of the unexplained nativity wealth gap at that specific percentile.
4.2 Propensity score matching
The implementation of PSM follows the subsequent steps.Footnote 23 First, a probit regression for the probability of being an immigrant (mixed) household is estimated. One advantage of SHARE is the availability of many variables on various aspects of individuals’ and households’ lives that can be used to perform the matching. Second, the households are matched on the basis of their estimated propensity score.
The choice of variables included in the regression is guided by the economic theory. In particular, wealth depends on savings, inherited wealth, and the rate of return on accumulated assets. As savings are not directly observed in SHARE, some standard socio-demographic factors related to saving behavior and assets returns are included.Footnote 24 Specifically, age, age squared, education, number of children, labor market status, self-assessed health,Footnote 25 and long-term health problemsFootnote 26 of both spouses are included, as well as country dummies. Early childhood conditionsFootnote 27 of both spouses are included as they may proxy for both the level of financial transfers received throughout life and the savings behavior, given the intergenerational transmission of financial behavior (see Section 2). As an income measure, total household income is included. Finally, dummies indicating whether the household ever received an inheritance and whether spouses have any sibling or any parent who is still alive are included in order to control both for having already received an inheritance and for the likelihood of receiving it in future.
As matching results are robust to the use of different algorithms, only results obtained through three-nearest neighbor (NN) matching are presented.Footnote 28 This procedure selects matching partners from the comparison group with the closest propensity score. As the comparison group of natives contains many observations, choosing more than one nearest neighbor increases the precision of the estimates (Caliendo and Kopeinig 2008). However, it is important to ensure that incomparable observations are not matched. One strategy to determine the region of common support consists in trimming the observations at which the propensity score density of the comparison group is the lowest. In the analysis, 5% of the observations are trimmed, leaving a sample size on the common support of 1682 migrant couples, 3499 mixed couples, and 3559 migrant single households.
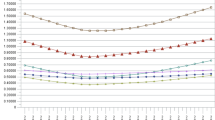
The matching quality is assessed by performing a number of tests: t test, standardized mean bias, and pseudo R2. Figure 5 shows that the matching procedure does a good job in matching propensity scores in the immigrant–native household comparison.Footnote 29 Further evidence on the quality of matching is presented in Tables 8 and 9 in the Appendix, which show the characteristics of migrants on the support (first column) and of the matched natives (second column) for migrant and mixed households, respectively.

Propensity score density before and after matching. Notes: These graphs show the propensity score density before and after three-nearest-neighbor matching for the first of the five SHARE imputed datasets. Native households: N = 38,582; migrant households: N = 1770 (on support: N = 1682). Observations are weighted using cross-sectional weights
Figure 5 also displays the support before (left hand-side panel) and after (right hand-side panel) trimming. As can be seen from a comparison of the two panels, the observations on the right hand side tail of the distribution, characterized by a very small propensity score density of native household observations, have been dropped from the analysis in order to guarantee a common support. While necessary to improve the quality of matching, a drawback of the trimming procedure is that it excludes a part of the sample for which proper comparisons cannot be found. Therefore, it is worth looking at the characteristics of the excluded households. These are shown in the third column of Tables A.2.1 and A.2.2 for migrant and mixed households, respectively. These households appear to be particularly disadvantaged, as they have lower education, worse health, and worse early childhood conditions on average than households on the support. They are also considerably younger, which might explain why they have higher total income, as social security is normally lower than labor income.
5 Results
5.1 The nativity wealth gap
Table 3 reports results on the nativity wealth gap for both immigrant and mixed households. The first column shows the unconditional wealth gap, which simply reflects mean differences in wealth between the two groups. The second column shows the unexplained wealth gap obtained from the Blinder-Oaxaca decomposition. As explained previously, this measures differences in the average returns to households’ characteristics, which are the same as those included in the matching procedure. The third column presents the average unexplained wealth gap measured on the common support region after matching the two groups. The wealth gap is measured both excluding and including pension wealth in the measure of total wealth in order to gain insights on the role of social security.
In all cases considered—with the exception of the unadjusted gap of mixed households when pension wealth is included—the average gap turns out positive and significant. With regard to the natives–immigrant household comparison, the B-O decomposition explains around 40% of the unconditional gap in the case of no pension wealth and almost 30% when pension wealth is included. The NN matching explains instead around 15% of the unconditional gap when pension wealth is excluded and 10% when it is included. In the natives–mixed household comparison, the average gap of mixed households—both excluding and including pension wealth—is larger when using the B-O decomposition and even more so when using NN matching.
Results on single households are presented in Table 4. The B-O decomposition and NN matching lead to a positive and significant gap, not very far in size to the unconditional one, when pension wealth is excluded. When pension wealth is included, both methods lead to a larger gap than the unconditional one: the gap using NN matching in particular is 60% higher.
These results point to two interesting findings. The first finding suggests that, after controlling for a large number of characteristics and by only using comparable observations, a large wealth gap emerges between native and migrant as well as mixed households. Second, the average gap obtained using NN matching is different and considerably higher than the one obtained using the B-O decomposition. It can be argued, however, that the average gap is not a comprehensive measure and may actually hide considerable heterogeneity of the gap along the wealth distribution, which happens to be exactly the case.
In order to show this, the last columns of Tables 3 and 4 report the wealth gap for specific percentiles of the wealth distribution. It is clear that the size of the gap varies considerably over the wealth distribution. Moving up the distribution, the gap is initially positive, meaning that migrants are worse off than comparable natives. Then, it decreases and eventually turns negative, signifying that migrant and mixed households in the upper part of the distribution are better off than comparable natives. If anything, when including pension wealth, the gap is even larger at lower wealth percentiles.
The development of the gap is better visualized graphically; therefore, Fig. 6 shows the horizontal distance between immigrant- and native-household wealth cumulative distribution functions (including pension wealth) at each percentile, both before and after having performed the matching. While the unexplained pension gap is increasing with wealth, the wealth gap measured after matching shows an opposite pattern, where the gap is higher in the lower part of the distribution, it decreases moving up the distribution until it turns negative around the 82nd percentile and ends up being large and negative in the upper part of the distribution.

Nativity wealth gap (including pension wealth) before and after matching of immigrant households. Notes: Native households: N = 38,582; migrant households: N = 1770 (on support: N = 1682). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights
In the case of mixed households (Fig. 7), a similar pattern of the wealth gap emerges after matching, with the difference that the gap measured before matching was around zero over the entire distribution. The gap after matching for mixed households turns negative at the 77th percentile when pension wealth is included.

Nativity wealth gap (including pension wealth) before and after matching of mixed households. Notes: Native households: N = 38,582; mixed households: N = 3683 (on support: N = 3499). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights
In order to shed some light on the factors that could help explain the pattern of the nativity wealth gap, Table 5 presents the mean value of individual and immigrants households’ characteristics (columns (1) and (2)), separately for households experiencing a positive or negative gap. A t test analysis of mean differences reveals that immigrant households who are better off than natives have a statistically significant higher probability to live in central Europe (and a corresponding lower probability of living in eastern and southern Europe). Moreover, they were originally born with much a higher probability in central or northern Europe. They have higher income on average, and 13pps higher probability of having received an inheritance or big gift. They have on average more education (2.65 more years of education for the male spouse, 2.57 more years for the female spouse) and a lower unemployment rate, and claim to be healthierFootnote 30 and less affected by long-term illnesses. Finally, it is interesting to notice the statistically significant differences in early childhood conditions: immigrant households experiencing a negative gap lived in bigger houses and, in the case of males, had more books available and performed better than classmates at ten years old.Footnote 31 Table 6 delivers a similar picture for mixed households.
In order to dig more into what could explain the negative gap characterizing higher wealth households, in column (5) of Tables 5 and 6 a t test of mean differences is conducted between the characteristics of immigrant households with a negative gap (column (2)) and their peers native households (that is, households above the percentile where the gap turns negative, column (3)). For both migrant and mixed households, hardly any significant difference can be observed.
These results highlight the importance of restricting the comparison only to sufficiently similar households, and of being able to measure the gap over all the wealth distribution. In sum, it is found that immigrant and mixed households are worse off on average than comparable natives, but this is not true for households in the upper part of the wealth distribution. Households in the lower part of the wealth distribution, on the other hand, are worse off than what the average gap suggests. Overall, the analysis suggests that worse-off immigrant households are more likely to have migrated from countries outside Europe, have lower income, are less healthy, less educated, and more likely to come from poorer families. Better-off immigrant households, on the contrary, are more likely to come from other European countries, are better educated, healthier, have higher income, and come from richer families, whereas no significant differences are found in comparison to their native counterpart.
However, one may argue that by pooling all immigrant households into a single group, a great deal of heterogeneity—that most likely characterizes these households—is hidden. In fact, one may wonder how different the size of the gap is for different migrants in the first place, and to what extent observable characteristics are able to explain the gap for different groups of migrant households. This concern is addressed in Section 6, where some specific groups of migrant households are separately analyzed.
5.2 Detailed decomposition analysis
This section proposes and then implements a strategy to perform a detailed decomposition analysis using matching as a decomposition tool. The aim of a detailed decomposition is to apportion the composition effect (or the structure effect) into components attributable to each explanatory variable. The strategy proposed is very intuitive and similar to the one used in other approaches based on reweighing.Footnote 32 The idea is simply to perform a sequential decomposition where the distribution of any covariate, Xk (or group of covariates), for one group is replaced by the distribution of that covariate for the second group, and then repeating the procedure adding variables on top of those already replaced, until the whole distribution of X is replaced. In practice, this is done by performing several matchings, each time adding a set of variables on top of those previously used.
In general, detailed decomposition is not an easy task in a non-linear setting where, depending on the decomposition method used, there may be a trade-off between the “adding-up” and “path independence” properties. The detailed decomposition of the composition effect is said to add up when \( {\Delta }_X^{\nu }={\sum}_{k=1}^K{\Delta }_{X_k}^{\nu } \). Fortin et al. (2011) explain that the adding-up property is automatically satisfied in linear settings like the standard B-O decomposition or the re-centered influence function (RIF-) regression procedure (Fortin et al. (2009)). In a non-linear setting, this property is satisfied in the sequential decomposition described previously.
A well-known problem related to this procedure, however, is that of “path-dependence,” meaning that the result of the decomposition will depend on the order in which the covariates are introduced.Footnote 33 As explained by Altonji et al. (2012), the sequential order of introduction of the variables in the decomposition should depend on the causal relationship between them or on the natural ordering that flows from the timing of variables. If this is not possible, the best approach is to try alternative orderings.
While a clear time flow is not clearly identifiable for most of the control variables used in this study, one exception is represented by early childhood conditions, which clearly temporally precede all other variables that may be relevant for wealth accumulation. Therefore, early childhood conditions will be introduced first in the sequential decomposition. Other three groups of variables are defined and sequentially added: basic demographics, total household income, and inheritance-related variables. As there is no natural ordering for these variables, a robustness will be presented where they are introduced in reverse order.
Figures 8 and 9 depict the sequential marginal changes in the gap distribution as the groups of variables are added, for migrant and mixed households, respectively. One thing stands out: early childhood conditions alone explain much of the upward shift of the wealth gap for households in the lower part of the wealth distribution and of the downward shift in the upper part of the distribution. Adding all the other three groups of variables leads only to a similarly large shift in the gap.

Detailed decomposition of the wealth gap, migrant households. Notes: Native households: N = 38,582; migrant households: N = 1770 (on support: N = 1682). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights

Detailed decomposition of the wealth gap, mixed households. Notes: Native households: N = 38,582; mixed households: N = 3683 (on support: N = 3499). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights
These variables are all arguably highly correlated. This is clear when comparing Figs. 8 and 9 with the corresponding Figures 13 and 14 in the Appendix that display the reverse order decomposition. Inheritance does not add anything on top of early childhood conditions on the left hand-side of the distribution. Not surprisingly, the contribution of inheritances shows up on the right hand-side of the distribution, as these are probably the only households who receive any inheritance. The other two sets of variables, basic demographics and total household income, are also highly related, and they do not add much on top of each other irrespective of the order in which they are introduced.
Overall, this analysis reveals the importance of early childhood conditions in the emergence of the wealth gap between natives and migrants as well as mixed households. Early childhood conditions are a proxy not only for family of origin’s wealth (and thus, for example, of potential financial transfers from parents to children) but also for many factors relevant to wealth accumulation that may have been transmitted to children: for example, savings behavior, financial literacy, education, and work choice. It turns out that migrants who experienced bad early childhood conditions are those who suffered most from migrating in terms of wealth. On the contrary, migrants characterized by good early childhood conditions appear to be better off than comparable natives.
6 Heterogeneity analysis
While the analysis performed relies on a pool of migrant households, the sample population is in fact quite heterogeneous. A drawback of using the matching procedure to study the wealth gap is that, unlike in a linear regression, it is not completely straightforward how to take into account the high heterogeneity that characterizes migrants within and across countries. Furthermore, the limited sample size does not allow for the study of very narrow categories of migrants. Nevertheless, the history of migration to European countries is characterized by some common patterns that might guide the choice of relevant comparison groups. Therefore, this section separately analyzes different groups of migrant households.
Individuals in the SHARE sample migrated mostly between 1950 and 1990. The time span from the 1950s to 1974 was characterized by two prominent migration flows, triggered by the rising demand for labor after the end of World War II and by decolonization, respectively (Van Mol and De Valk 2016). The first flow consisted of intra-European migration toward the richer Northwestern countries that recruited labor from the poorer Southern European countries. However, East–West mobility remained limited until the end of the Cold War.
The second flow, which occurred predominately during the 1960s and 1970s, consisted of migration from former colonies. A significant number of people moved to Belgium, France, the Netherlands, the UK, Portugal, and Italy, the former colonial powers (Van Mol and De Valk 2016).Footnote 34 Many of these people were born in the colonies but were of European origin and could therefore integrate relatively quickly. However, migrants who were of non-European descent were mainly poorer individuals and were often encouraged to migrate to fill the labor market for low- and un-skilled workers. Due to fear of foreign influence and job security, these groups were often discriminated against (Bade 2008; Bell et al. 2010). Several countries granted citizenship or special legal status to migrants from former colonies, whereas under normal circumstances several years of residency and employment in a country were necessary to obtain legal status (Fassmann and Munz 1992).
The period from 1974 to the 1990s was instead characterized by the effects of the oil crisis and the reduction in the demand for labor. This eventually led Northwestern European countries to implement stricter immigration rules in order to reduce migration flows. Migration did not stop, but it was instead transformed in large part to family reunifications. In addition, migration from Turkey and North Africa consistently rose, while Southern European countries, which had historically been emigration countries, steadily became common immigration destinations by non-European countries (Bade 2008).
This brief account of the history of migration to Europe helps identify some interesting comparison groups. In the following section, three comparisons are performed. The first comparison will focus on the wealth gap distribution of individuals who migrated within Europe vs. individuals who migrated from outside Europe. This comparison is relevant given the different characteristics of these two migration flows. The relative geographical and cultural vicinity of European countries should predict lower costs and risks of both migrating and settling, which in turn could determine a different development of the gap. At the same time, while some migrants of European origin who moved from former overseas colonies may have found it easier to settle due to their colonial ties and privileged status, only a fraction of the main sample includes this group.
The second comparison will be based on age at migration. Adult migrants who actively decided to migrate most likely did so in order to move to a country with a higher labor demand and therefore had limited time to settle. On the contrary, those who migrated at a young age—most likely by simply moving with their parents—may have completed some schooling in the destination country and have had more time to settle. Overall, the younger the age at migration, the higher the potential level of assimilation.
Finally, the third comparison will contrast households who hold the citizenship of the destination country with those who do not. Holding a country’s citizenship represents a crucial step toward assimilation in the country of residence, because it generally requires several continuous years of residency and employment or strong cultural ties like in the case of migration from former colonies. Moreover, it allows individuals to fully benefit from the country’s social and political rights.
Figure 10 presents the distribution of the gap for European migrant households (top panel), as opposed to non-European migrants (bottom panel).Footnote 35 In absolute terms, the gap measured after matching is generally larger for European than for non-European migrants over the entire wealth distribution. This is misleading, however, because European migrant households are much better off than non-European ones, with a median wealth of around 327,000 Euro as opposed to 158,000 Euro, respectively.Footnote 36 Therefore, the important takeaway is the relative gap, which is the gap relative to adjusted wealth. Table 10 in the Appendix shows the relative gap by selected percentiles and clarifies that the positive gap is actually always lower for European migrants in relative terms.Footnote 37

Nativity wealth gap of immigrant households, by area of origin. Notes: European households include only households where both spouses migrated from another European country; non-European households include only households where both spouses migrated from a non-European country. Native households: N = 38,582; European migrant households: N = 923 (on support: N = 877); non-European migrant households: N = 630 (on support: N = 599). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights
Figure 11 displays the distribution of the gap for migrants who migrated before the age of 18 (top panel), as opposed to those who migrated after the age of 18 (bottom panel).Footnote 38 It emerges clearly from these graphs that those households who migrated at younger ages perform much better than those who migrated at older ages. This is true both in terms of wealth level and in terms of wealth gap with respect to natives. Households who migrated earlier have a median wealth of almost 400,000 Euro, as opposed to 217,000 Euro for those who migrated later.Footnote 39 Overall, the relative gap is consistently smaller for those who migrated earlier, as shown in Table 10 in the Appendix. This is also the only group for whom an average gap not statistically significantly different from zero is found (see Table 7). For those who migrated at older ages, the gap is instead relatively large over the entire wealth distribution. The costs of migration are likely high for these households, in part due to language barriers, lack of state-recognizable schooling or university qualifications, and other factors that affect one’s ability to settle and find work.

Nativity wealth gap of immigrant households, by age at migration. Notes: Households who migrated before the age of 18 include households where at least one spouse migrated before 18; households who migrated after the age of 18 include households where both spouses migrated after 18. Native households: N = 38,582; households migrated before the age of 18: N = 641 (on support: N = 609); households migrated after the age of 18: N = 1129 (on support: N = 1073). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights
Finally, Fig. 12 displays the gap distribution of households that hold the citizenship of the destination country and of households who do not.Footnote 40 As expected, the gap among households holding citizenship is consistently smaller than among households who do not, and this is true in both absolute and relative terms (see Table 10 in the Appendix). Overall, origin, age at migration, and citizenship are all important determinants of the wealth gap. Among the three, early migration and possession of the destination country’s citizenship stand out as important factors in closing the wealth gap in particular.

Nativity wealth gap of immigrant households, by citizenship. Notes: Households with citizenship include households where both spouses hold the citizenship; households without citizenship include households where none of the spouses hold the citizenship. Native households: N = 38,582; households with citizenship: N = 761 (on support: N = 723); households without citizenship: N = 804 (on support: N = 759). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights
7 Conclusions
This study assesses the wealth gap between foreign-born and native households in Europe. Shedding light on this topic is important for a number of reasons, most notably to provide information on the economic integration of the sizable number of older immigrants who have been living in Europe since young ages, and to gauge whether they are a group at risk of poverty in retirement. The existence and direction of the nativity wealth gap is not trivial, and economic theory does not provide a straightforward answer. Thus, the native–immigrant wealth gap necessarily boils down to an empirical question.
This study also adds to the literature with respect to the empirical strategy adopted to measure the gap. The limited literature in measuring wealth gaps relies on either linear wealth estimation or the classical Blinder-Oaxaca decomposition method, both of which present several issues. First of all, they use the undesirable assumption of linearity. Second, they only measure the average gap, which hides heterogeneity of the gap across the wealth distribution. Third, they may be subject to misspecification due to differences in the supports of the empirical distributions of the two analyzed groups. Thus, this study adopts a non-parametric alternative to the B-O decomposition based on propensity score matching. This approach does not require the specification of any function, simulates the gap only for the common-support sub-population, and allows the estimation of the gap over the entire distribution of wealth.
This study highlights the importance of restricting analysis to comparable households and additionally draws attention to other possible telling measures of the wage gap besides the commonly used mean values. The use of the mean gap is often misleading as it hides an interesting distribution, in which immigrant households in the lower part of the wealth distribution are worse off and those in the upper part of the wealth distribution are better off than comparable natives. The latter group migrated in most cases from the richer European countries, has higher income, is better educated, healthier, and has a richer family background. Furthermore, a detailed decomposition reveals the importance of early childhood conditions in explaining the emergence of a wealth gap.
A drawback of the analysis is that, due to sample size limitations and the empirical approach used, a refined analysis of the gap for very narrow categories of migrant households is not be feasible. This is a limitation given the high heterogeneity of migrants within and across countries. Nevertheless, a heterogeneity analysis is presented that attempts to partially overcome this limitation by comparing some meaningful groups of migrants. It emerges that some households consistently experience a smaller wealth gap. In particular, those who migrated from within Europe have a smaller relative gap than those who migrated from outside Europe. This result is even stronger for households who migrated at young ages with respect to those who migrated as adults, as well as for those who are citizens of the destination country.
Further research is needed in order to causally assess the origin of this “unexplained” wealth gap. Furthermore, it should be noticed that despite the wealth gap found when comparing migrant and native households, it could be the case that households who migrated are better off than they would have been by not migrating. This is an empirical question that is also left to future research.
Notes
An exception is Sevak and Schmidt (2014), who use data from the Health and Retirement Study linked with restricted data from the Social Security Administration in order to estimate future Social Security benefits and use self-reported data on Social Security benefits for those who already receive them.
Borjas and Bratsberg (1996) explain that people who decide to migrate and stay in the receiving country may be positively or negatively self-selected based on their observable or unobservable characteristics. When the correlation between skills in the two countries is sufficiently high and when the destination country has more dispersion in its earnings distribution, immigrants are positively selected (have above average earnings in both the source and destination countries). When the earnings distribution in the source country has a larger variance than the earnings distribution in the destination country, immigrants are negatively selected (have below-average earnings in both the source and destination countries). Return migration accentuates the initial selection: the return migrants are the “worst of the best” in the case of initial positive selection, and the “best of the worst” in the case of initial negative selection. Thus, it is possible that permanent foreign-born individuals end up in the upper and lower parts of the destination-country wealth distribution, depending on the initial selection.
Sevak and Schmidt (2014) notice that working “off the books” may be another reason for lower benefits.
As a basic principle, any EU citizen should be able to practice his or her profession freely in any member state. However, the practical implementation of this principle is often hindered by national requirements for access to certain professions in the destination country.
See Börsch-Supan (2017a), Börsch-Supan (2017b), Börsch-Supan (2017c), and Börsch-Supan (2017d). Wave 3 of SHARE is called SHARELIFE and includes different information with respect to the regular waves as it focuses on people’s life histories. For this reason, it is not used here. Wave 1 is excluded because several variables are coded differently than in the following waves and are thus not fully comparable.
To be more precise, interviews for wave 2 were conducted in 2006 and 2007, for wave 4 in years 2010 to 2012, for wave 5 in 2013, and for wave 6 in 2015.
Administrative data would not present this problem; however, they generally do not cover the whole individual’s wealth, they are not available Europe-wide, and, most importantly, they do not have the rich set of individual characteristics necessary for the analysis of this paper. In terms of other European surveys, the Household Finance and Consumption Survey (HFCS) also present a high number of missing observations, despite being designed specifically to survey wealth. Besides, the sample we are interested in (age 50+) would be smaller, and several other important variables would be not available.
Differently from wealth variables, which are asked at the household level, pension entitlements are asked to each interviewed individual.
The included countries are Austria, Germany, Sweden, Netherlands, Spain, Italy, France, Denmark, Greece, Switzerland, Belgium, Czech Republic, Poland, Ireland, Luxembourg, Slovenia, and Estonia. Hungary and Portugal are dropped because of lack of information on early childhood conditions. Israel is excluded as it is not part of Europe.
Social security, occupational, and early retirement pensions are included, but disability pension is not. While it is asked to individuals whether they receive any unemployment or social assistance pension, it is not asked whether they are eligible for any of them. For this reason, unemployment and social assistance pensions are excluded from the computation of pension wealth.
Statutory retirement ages and replacement rates for the average workers, separately for men and women, are obtained from OECD (2016).
University of California Berkeley (USA) and Max Planck Institute for Demographic Research (Germany) (2016).
Dustmann and Weiss (2007) show, for example, that in the UK migrants return home mainly during the first half decade of being in the destination country and after five years the migrant survival probability tends to stabilize. They also note that “for many aspects of analysis of immigrant behavior, it is convenient to define a migration as temporary if the migrant leaves the country before reaching retirement age.” (Footnote 2, p. 255).
Northern Europe includes Sweden and Denmark; Central Europe includes Austria, Germany, the Netherlands, France, Switzerland, Belgium, Ireland, and Luxembourg; Southern Europe includes Spain, Italy, and Greece; Eastern Europe includes Czech Republic, Poland, Slovenia, and Estonia.
Hunkler et al. (2015) comment on the case of Eastern European transformation states. Due to the independence of Estonia from Russia, the split of Czechoslovakia into Czech Republic and Slovakia, and of Slovenia from Yugoslavia, a number of individuals are coded as immigrants, even if it is debatable to define them as such. The same applies to countries that unified, like East and West Germany. If the individuals actually never moved, the gap should be null on average as they are actually natives, so including them in the analysis should lead to a lower bias of the gap. A robustness analysis where these problematic individuals are excluded from the sample actually leads to a bigger gap, confirming this hypothesis. It should be noticed, however, that by doing so also individuals who actually moved might be excluded.
All monetary values are expressed in German 2005 Euro, using exchange rates that adjust for purchasing power parity.
This may in part depend on an imprecise definition of immigrants in some of these countries (see Footnote 16), but the fact that the vast majority of immigrants in this area comes from other Eastern European countries makes it reasonable to expect similar wealth levels.
The exact question in the survey states: “have you or your wife/husband ever received a gift or inherited money, goods, or property worth more than 5000 Euro?”
The latter component may be due to unobservables or to actual differences in returns, as would be in the presence of discrimination for example. In general, in the absence of stronger assumptions, it is not possible to interpret the different returns as a causal treatment effect, see Fortin et al. (2011).
See Altonji and Doraszelski (2005).
Barsky et al. (2002) also use a non-parametric alternative to B-O in order to avoid imposition of any functional form on the wealth-earnings relationship, showing that misspecification of the conditional expectation function may result in errors in inference regarding the part of the gap explained by differences in the distribution of explanatory variables.
See Caliendo and Kopeinig (2008).
Self-assessed health is ranked from 1 (“excellent”) to 5 (“poor”).
The question reads: “Some people suffer from chronic or long-term health problems. By chronic or long-term we mean it has troubled you over a period of time or is likely to affect you over a period of time. Do you have any such health problems, illness, disability or infirmity?”
The early childhood condition variables are the number of rooms in the house where respondent was living at age 10 divided by the number of people living in the house, the number of books present in the house at 10, the school performance at ten compared to the other children in the class and health at ten. School performance at ten is ranked from 1 (“much better”) to 5 (“much worse”).
Specifically, besides 3-nearest neighbor, also one-to-one matching with replacement and radius matching with caliper 0.01 were implemented.
The graph refers to one of the five imputed samples, but the same graphs for the other four samples show a similarly good match. This is not surprising since the control variables used in the matching procedure present a rather small percentage of missing values.
Health is ranked from 1 (“excellent”) to 5 (“poor”).
School performance is ranked from 1 (“much better”) to 5 (“much worse”).
Fortin et al. (2011) notice, for example, that “In principle, other popular methods in the program evaluation literature such as matching could be used instead of reweighing.” (Footnote 56, p. 68).
Basically, the path-dependence problem is an omitted variable problem. See Fortin et al. (2011).
Even if former Spanish colonies were since long independent, migrants from Latin America still enjoy a more favorable legal treatment than other nationalities in Spain, motivated by the strong ties to the Latin American region (Hierro 2016). Thus, Spain might be added to this list.
Only households where both spouses migrated from European countries (top panel) or where both migrated from non-European countries (bottom panel) are included.
The average amounts to 425,000 Euro for European migrant households and 255,000 Euro for non-European ones.
Interestingly, also, the negative part of the gap on the right hand-side of the distribution is lower for European migrant households in relative terms.
The analysis was performed also using different migration age thresholds (10 years and 16 years), but, as very similar results were obtained, only the case of migration before/after the age of 18 is presented. The household is considered to have migrated before 18 if at least one of the spouses migrated before 18 and to have migrated after 18 if both spouses migrated after 18.
The average amounts to 473,574 Euro for households where at least one spouse migrated before 18 and 308,345 Euro for households where both spouses migrated after 18.
Households with citizenship include households where both spouses hold citizenship; households without citizenship include households where none of the spouses hold citizenship.
Alternatively, the “across-approach” would consist in averaging each unit’s m propensity score, matching units based on their averaged scores, and finally estimating the mean gap from this single set of matched controls. Sample weights are used when estimating the gap.
References
Alessie R, Angelini V, Van Santen P (2013) Pension wealth and household savings in Europe: evidence from SHARELIFE. Eur Econ Rev 63:308–328
Altonji JG, Doraszelski U (2005) The role of permanent income and demographics in black/white differences in wealth. J Hum Resour 40(1):1–30
Altonji JG, Bharadwaj P, Lange F (2012) Changes in the characteristics of American youth: implications for adult outcomes. J Labor Econ 30(4):783–828
Amuedo-Dorantes C, Pozo S (2002) Precautionary saving by young immigrants and young natives. South Econ J 69:48–71
Bade K (2008). Migration in European history, Volume 4. John Wiley & Sons
Barsky R, Bound J, Charles KK, Lupton JP (2002) Accounting for the black–white wealth gap: a nonparametric approach. J Am Stat Assoc 97(459):663–673
Bauer TK, Sinning MG (2011) The savings behavior of temporary and permanent migrants in Germany. J Popul Econ 24(2):421–449
Bauer TK, Cobb-Clark DA, Hildebrand VA, Sinning MG (2011) A comparative analysis of the nativity wealth gap. Econ Inq 49(4):989–1007
Bell S, Alves S, de Oliveira ES, Zuin A (2010) Migration and land use change in Europe: a review. Living Rev Landsc Res 4:2
Blinder AS (1973) Wage discrimination: reduced form and structural estimates. J Hum Resour 8:436–455
Borjas GJ (1994) The economics of immigration. J Econ Lit 32(4):1667–1717
Borjas GJ (2002) Homeownership in the immigrant population. J Urban Econ 52(3):448–476
Borjas G, Bratsberg B (1996) Who leaves? The outmigration of the foreign-born. Rev Econ Stat 78(1):165–176
Börsch-Supan A (2017a). Survey of health, ageing and retirement in Europe (share) wave 2. Release version: 6.0.0. SHARE-ERIC. Data set. https://doi.org/10.6103/SHARE.w2.600
Börsch-Supan, A. (2017b). Survey of health, ageing and retirement in Europe (share) wave 4. Release version: 6.0.0. SHARE-ERIC. Data set. https://doi.org/10.6103/SHARE.w4.600
Börsch-Supan A (2017c). Survey of health, ageing and retirement in Europe (share) wave 5. Release version: 6.0.0. SHARE-ERIC. Data set. https://doi.org/10.6103/SHARE.w5.600
Börsch-Supan A (2017d). Survey of health, ageing and retirement in Europe (share) wave 6. Release version: 6.0.0. SHARE-ERIC. Data set. https://doi.org/10.6103/SHARE.w6.600
Caliendo M, Kopeinig S (2008) Some practical guidance for the implementation of propensity score matching. J Econ Surv 22(1):31–72
Christelis D et al. (2011). Imputation of missing data in waves 1 and 2 of share. Technical report, Centre for Studies in Economics and Finance (CSEF), University of Naples, Italy
Cobb-Clark DA, Hildebrand VA (2006) The wealth and asset holdings of US-born and foreign-born households: evidence from SIPP data. Rev Income Wealth 52(1):17–42
Constant AF, Roberts R, Zimmermann KF (2009) Ethnic identity and immigrant homeownership. Urban Stud 46(9):1879–1898
De Arcangelis G, Joxhe M (2015) How do migrants save? Evidence from the British household panel survey on temporary and permanent migrants versus natives. IZA J Migr 4(1):1
De Luca G, Celidoni M, and Trevisan E (2015). Item nonresponse and imputation strategies in share wave 5. In Malter F and Börsch-Supan A (Eds.), SHARE Wave 5: innovations & methodology, chapter 7, pp. 85–100. Munich: MEA, Max Planck Institute for Social Law and Social Policy
Dustmann C (2000) Temporary migration and economic assimilation. Swedish Econ Policy Rev 7(2):213–244
Dustmann C, Weiss Y (2007) Return migration: theory and empirical evidence from the UK. Br J Ind Relat 45(2):236–256
Fassmann H, Munz R (1992) Patterns and trends of international migration in Western Europe. Popul Dev Rev 18:457–480
Favreault M and Nichols A (2011). Immigrant diversity and social security: recent patterns and future prospects. Boston College Center for Retirement Research Working Paper (2011–8)
Fortin N, Lemieux T, Firpo S (2009) Unconditional quantile regression. Econometrica 77(3):953–973
Fortin N, Lemieux T, Firpo S (2011) Decomposition methods in economics. Handbook Labor Econ 4:1–102
Frölich M (2007) Propensity score matching without conditional independence assumption with an application to the gender wage gap in the United Kingdom. Econ J 10(2):359–407
Haliassos M, Jansson T, Karabulut Y (2016) Incompatible European partners? Cultural predispositions and household financial behavior. Manag Sci 63(11):3780–3808
Hierro M (2016) Latin American migration to Spain: main reasons and future perspectives. Int Migr 54(1):64–83
Hill J (2004). Reducing bias in treatment effect estimation in observational studies suffering from missing data. ISERP working papers (04-01)
Hunkler C, Kneip T, Sand G, Schuth M (2015) Growing old abroad: social and material deprivation among first- and second generation migrants in Europe. In: Börsch-Supan A, Kneip T, Litwin H, Myck M, Weber G (eds) Ageing in Europe—supporting policies for an inclusive society. De Gruyter, Berlin, pp 199–208
Kahanec M, Shields MP (2013) The working hours of immigrants in Germany: temporary versus permanent. IZA J Migr 2(1):14
Little RJ and Rubin DB (2014). Statistical analysis with missing data, Volume 333. John Wiley & Sons
Lusardi A, Mitchell OS (2014) The economic importance of financial literacy: theory and evidence. J Econ Lit 52(1):5–44
McKernan S-M, Ratcliffe C, Simms M, Zhang S (2014) Do racial disparities in private transfers help explain the racial wealth gap? New evidence from longitudinal data. Demography 51(3):949–974
Menchik PL, Jianakoplos NA (1997) Black-white wealth inequality: is inheritance the reason? Econ Inq 35(2):428–442
Mitra R, Reiter JP (2016) A comparison of two methods of estimating propensity scores after multiple imputation. Stat Methods Med Res 25(1):188–204
Mizala A, Romaguera P, Gallegos S (2011) Public–private wage gap in Latin America (1992–2007): a matching approach. Labour Econ 18:S115–S131
Ñopo H (2008) Matching as a tool to decompose wage gaps. Rev Econ Stat 90(2):290–299
Oaxaca R (1973) Male-female wage differentials in urban labour markets. Int Econ Rev 14(3):693–709
OECD (2016). Pensions at a glance database. https://stats.oecd.org/Index.aspx?DataSetCode=PAG
Osili UO and Paulson AL (2004). Prospects for immigrant-native wealth assimilation: evidence from financial market participation. FRB of Chicago Working Paper (2004–18)
Osili UO, Paulson AL (2008) Institutions and financial development: evidence from international migrants in the United States. Rev Econ Stat 90(3):498–517
Qu Y, Lipkovich I (2009) Propensity score estimation with missing values using a multiple imputation missingness pattern (MIMP) approach. Stat Med 28(9):1402–1414
Sevak P, Schmidt L (2014) Immigrants and retirement resources. Soc Sec Bull 74:27
Sinning M (2010) Homeownership and economic performance of immigrants in Germany. Urban Stud 47(2):387–409
Stuck S, Zuber S, Kotte M, Franzese F, Gruber S, and Birkenbach T (2018). SHARE release guide 6.1.1. http://www.share-project.org/fileadmin/pdf_documentation/SHARE_release_guide_6-1-1.pdf
University of California Berkeley (USA) and Max Planck Institute for Demographic Research (Germany) (2016). Human mortality database. http://www.mortality.org
Van Buuren S, Brand JP, Groothuis-Oudshoorn C, Rubin DB (2006) Fully conditional specification in multivariate imputation. J Stat Comput Simul 76(12):1049–1064
Van Mol C and De Valk H (2016). Migration and immigrants in Europe: a historical and demographic perspective. In Integration processes and policies in Europe, pp. 31–55. Springer
Acknowledgements
I thank the Editor-in-Chief Klaus Zimmermann and two anonymous referees for their helpful comments and suggestions. I am also grateful for the helpful comments of Axel Börsch-Supan, Tabea Bucher-Koenen, Rob Alessie, Adriaan Kalwij, Michael Hurd, Romuald Meango, and all the participants at the MEA Seminar, Spring Meeting of Young Economists (Halle, 2017) and the Royal Economic Society Annual Conference (Bristol, 2017). The SHARE data collection has been primarily funded by the European Commission through FP5 (QLK6-CT-2001-00360), FP6 (SHARE-I3: RII-CT-2006-062193, COMPARE: CIT5-CT-2005-028857, SHARELIFE: CIT4-CT-2006-028812), and FP7 (SHAREPREP: N.211909, SHARE-LEAP: N.227822, SHARE M4: N.261982). Additional funding from the German Ministry of Education and Research, the US National Institute on Aging (U01 AG09740-13S2, P01 AG005842, P01 AG08291, P30 AG12815, R21 AG025169, Y1-AG-4553-01, IAG BSR06-11, OGHA 04-064), and various national funding sources is gratefully acknowledged (see www.share-project.org).
Funding
Open access funding provided by Max Planck Society.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that she has no conflict of interest.
Additional information
Responsible editor: Klaus F. Zimmermann
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Inference with multiple imputations
The analysis in this study uses the imputations provided by SHARE for variables with missing values. As in any other survey, in fact, some variables present a fraction of missing values which may range from very small (for example, in the case of age and education) to very high, as is typical of monetary variables. De Luca et al. (2015) present some statistics on items non-response for monetary variables in the fifth wave of SHARE and show that it presents high variability depending on the specific item and country considered. Non-response to questions on the value of house in Slovenia or the amount in bank accounts in Luxembourg, for example, is over 60%. This contrasts to other countries, like Denmark and Sweden, where item non-response is generally lower than 10% for all variables considered. The cross-country average of item non-response ranges between a minimum of 9% for payments from public old age pensions to a maximum of 36% for amount hold in bank accounts (De Luca et al. 2015).
Item non-response has two negative consequences. The former is that using only observations for which there are no missing values in any of the variables the researcher needs would drastically reduce the sample size. The latter, and most important, is that most likely missingness is non-random, which means that any estimate obtained using only complete observations would produce biased results (Little and Rubin 2014). For these reasons, using imputations is advisable.
It must be clarified, however, that research on the use of imputations in matching is meager and it mostly consists of simulations which have the aim of understanding which method delivers the smallest bias (Hill 2004; Qu and Lipkovich 2009; Mitra and Reiter 2016). Furthermore, to the best of this author’s knowledge, analytical derivations of multiple imputation variance estimators for matching do not exist. Nevertheless, existing simulations show that multiple imputation methods outperform in terms of bias reduction the methods which use only complete cases and, thus, assume the strongest possible assumption of data “missing completely at random” (MCAR).
The multiple imputation (MI) approach used for SHARE rests instead on the less stringent assumption of data “missing at random” (MAR). This assumption states that the missingness of each variable depends only on other variables in the system and not on the values of the variable itself. As noticed by Christelis et al. (2011), this is actually unlikely to hold for financial variables, which are more likely subject to a yet different type of missingness mechanism where data are “missing not at random” (MNAR). Nevertheless, Van Buuren et al. (2006) show that MI produces less biased results than using only complete cases even in the presence of MNAR data.
Given this premise, this study adopted the following strategy: all linear estimates are obtained using Rubin’s rule, which delivers the correct coefficients and standard errors (see Little and Rubin 2014). Formally, the estimate of interest obtained using the M imputed datasets is the average of the M separate estimates (Eq. (6)):
and the total variance, TV, of these estimates is composed by the sum of the within-imputation variance and the between-imputation variance (Eq. (7)):
As regards results obtained through PSM, estimates of the gap are derived using the so-called “within-approach” (Mitra and Reiter (2016)), which consists in estimating the propensity scores in each dataset—thus obtaining M values of each unit’s propensity score—and then matching treated and control units within each completed dataset. In the final step, the resulting M estimates of the gap are averaged to obtain an estimate of the mean gap.Footnote 41 As noticed by Qu and Lipkovich (2009), the matching estimator does not account for the uncertainty which derives from using imputations. For this reason, a bootstrap technique—with 1000 replications for each imputed dataset—is used in order to get standard errors for the PSM estimates.
Finally, the average of individuals’ wealth over the m imputations is calculated in order to obtain a single wealth distribution for natives, migrants, and matched households, respectively.
1.2 Additional material

Reverse-order detailed decomposition of the wealth gap, migrant households Notes: Native households: N = 38,582; migrant households: N = 1770 (on support: N = 1682); mixed households: N = 3683 (on support: N = 3499). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights

Reverse-order detailed decomposition of the wealth gap, mixed households Notes: Native households: N = 38,582; mixed households: N = 3683 (on support: N = 3499). Monetary values are expressed in German 2005 Euro. Observations are weighted using cross-sectional weights
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ferrari, I. The nativity wealth gap in Europe: a matching approach. J Popul Econ 33, 33–77 (2020). https://doi.org/10.1007/s00148-019-00735-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00148-019-00735-8