4.1. Simulation Study
In this simulation study, we focus on multimodal true distributions. We simulate random samples
,
from a mixture of three normal distributions. We denote by
, for all
, the cdf of the distribution
. The data-generating process (DGP) is specified as:
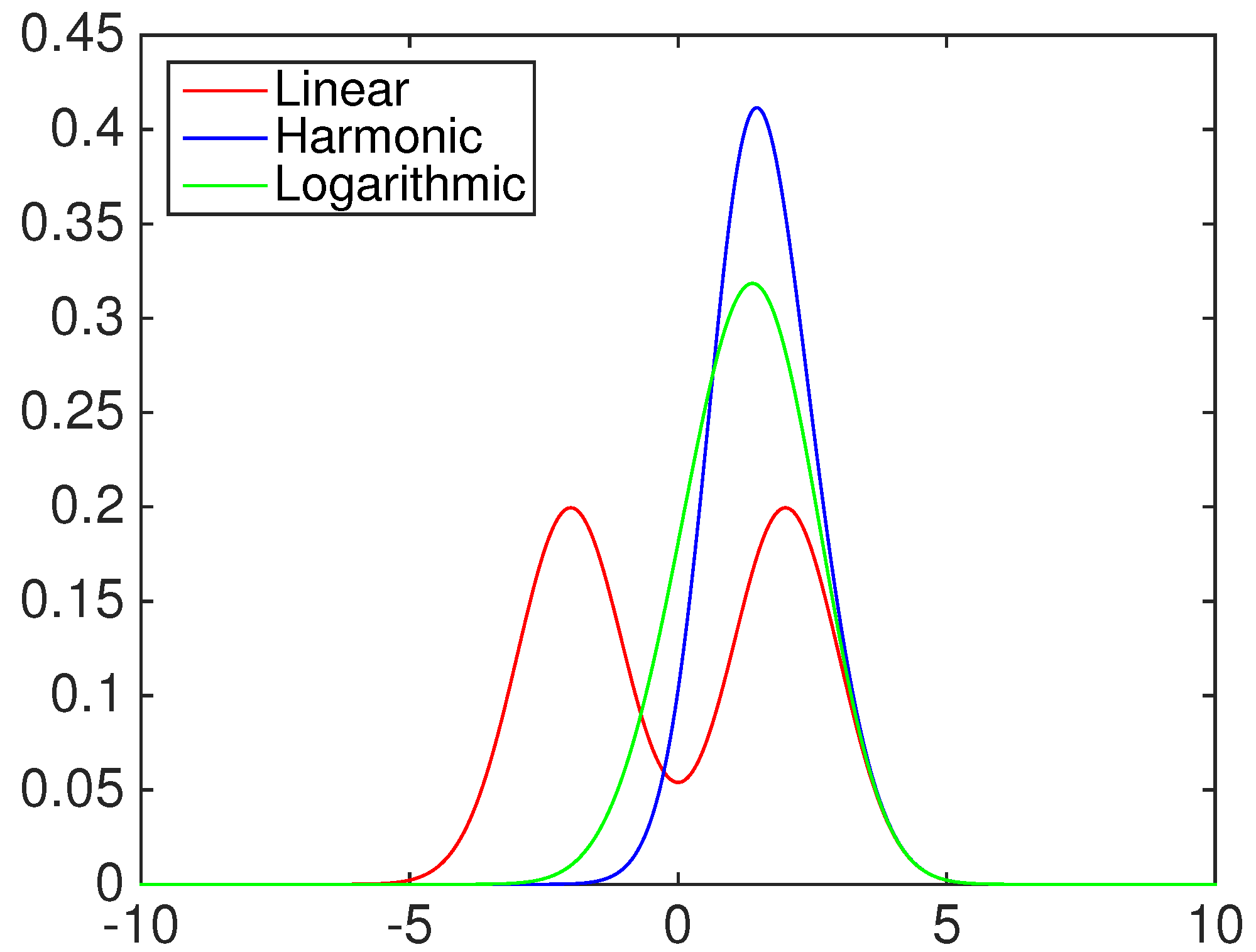
where
. Moreover, we assume that the set of predictive models includes two normal distributions:
and
. The distributions of the combination schemes compared in our simulation experiments are:
the equally-weighted model (EW):
where
ω is the combination weight equal to
.
correspond to Equations (3)–(5), for linear, harmonic and logarithmic pool, respectively, when
;
the beta calibration model (BC1):
where
, and
, with
, is defined by Equations (3)–(5);
the two-component beta mixture calibration model (BC2):
where
and
is the same as in the BC1 model.
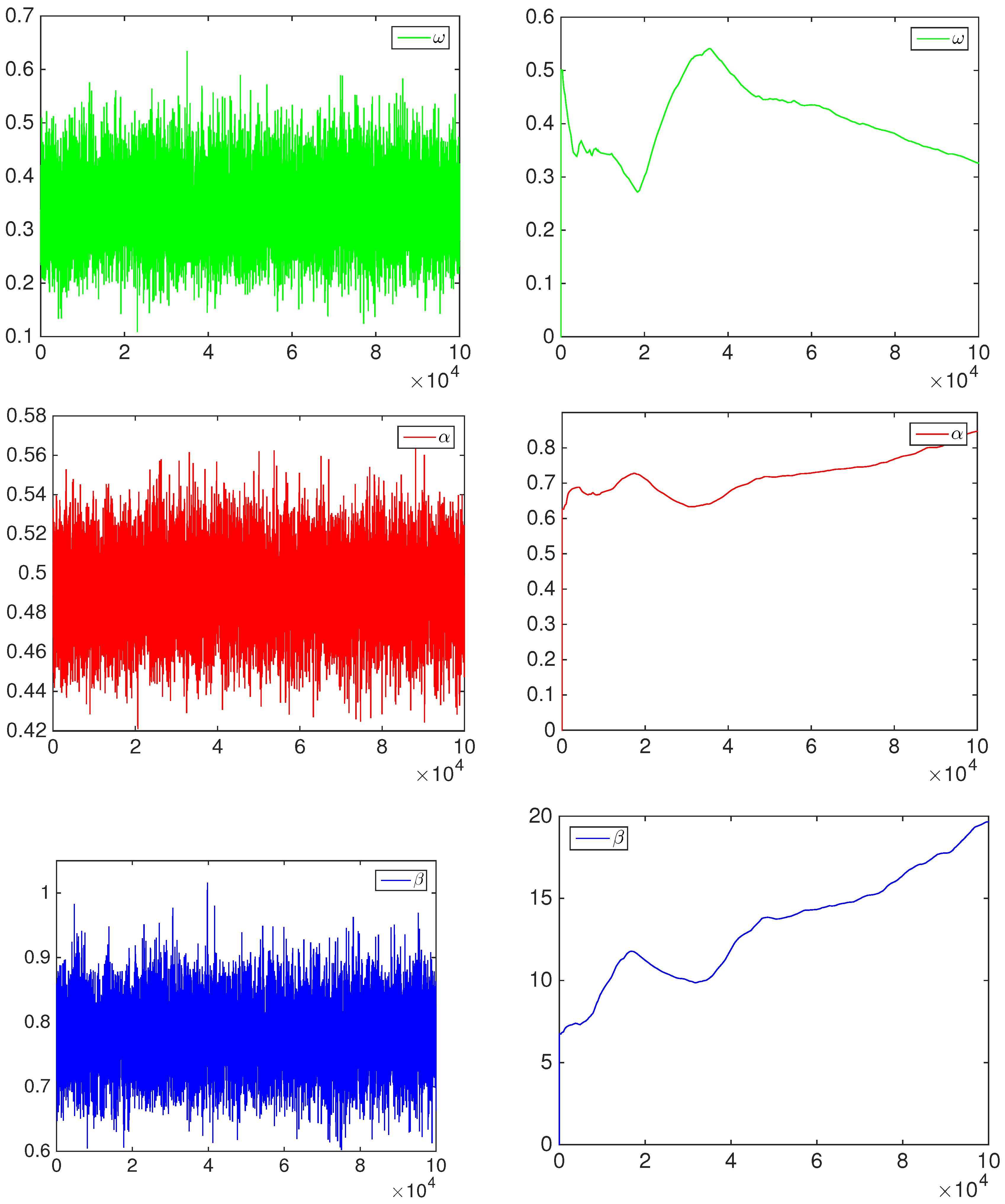
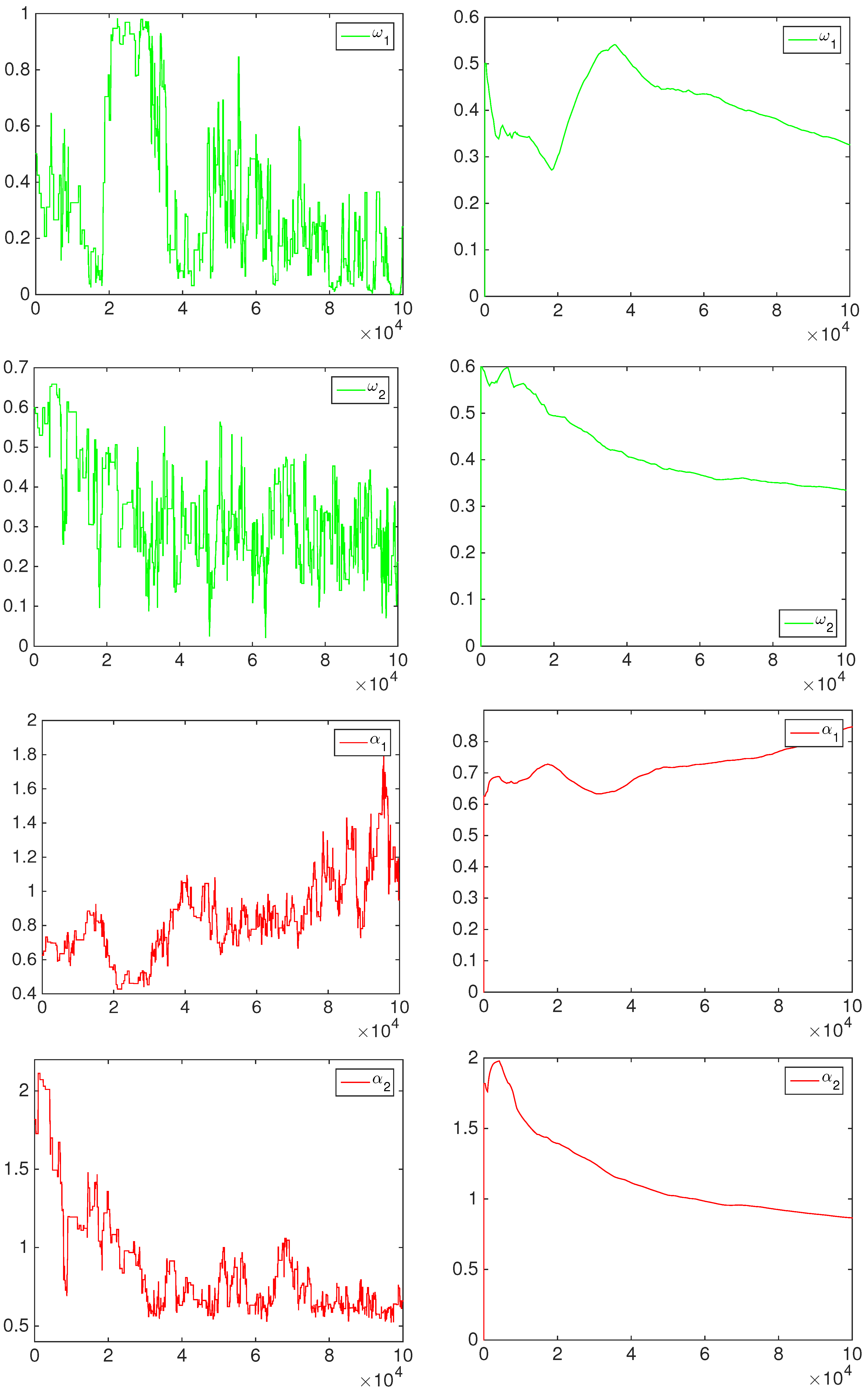
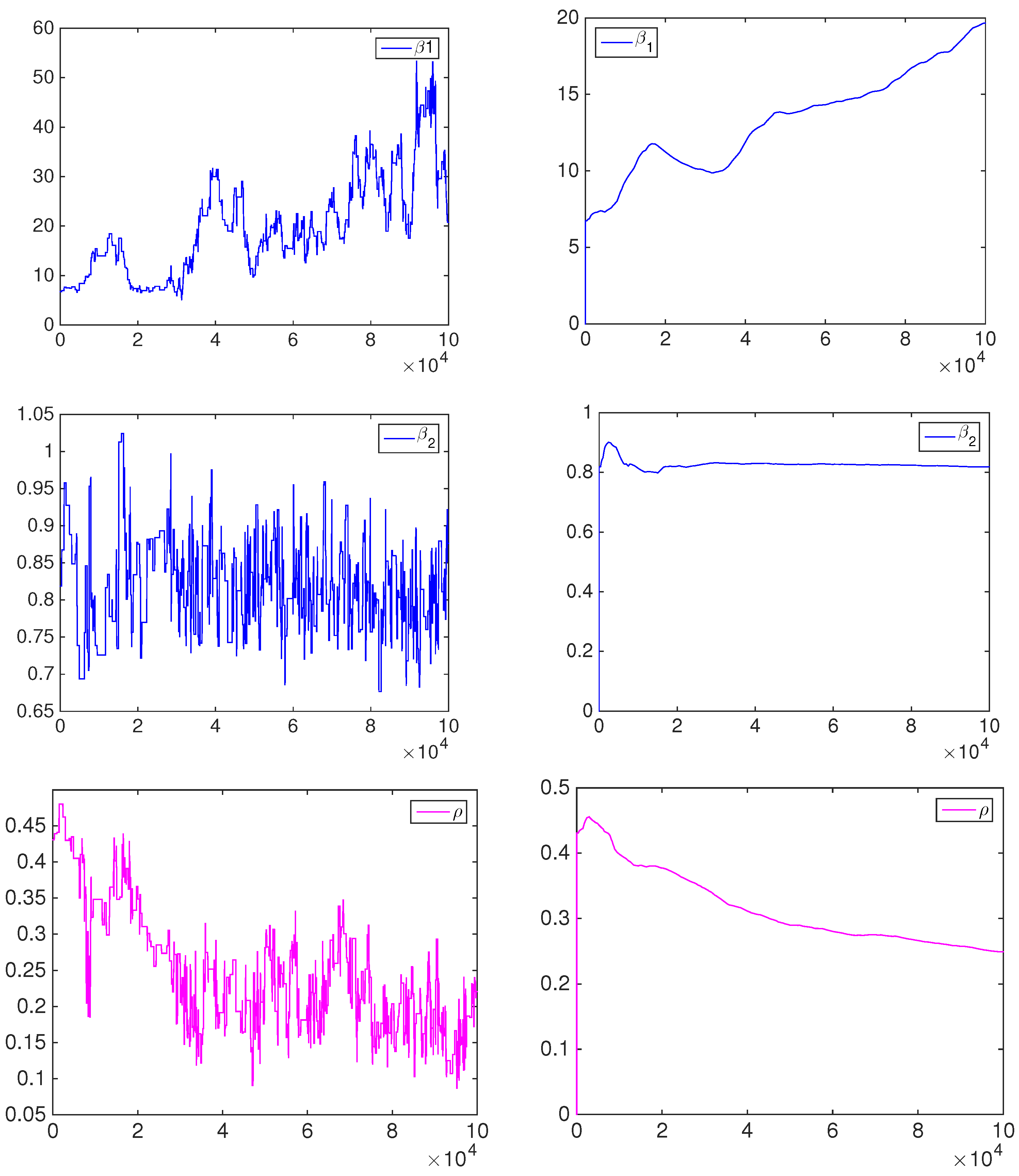
The posterior approximation is based on a set of 50,000 MCMC iterations after a burn-in period of 50,000 iterations. An example of MCMC output is given in the
Appendix. In order to reduce the dependence in the samples, we thin out every 50th draw after the burn-in period. Therefore, we obtain 1000 samples, which are used to approximate all of the posterior quantities of interest.
The posterior means of the BC1 and BC2 parameters (represented by the vector
θ) are reported in
Table 1 for the linear combination models, in
Table 2 for the harmonic combination models and in
Table 3 for the logarithmic combination models, according to
. In the tables,
and
stand for the parameters of the beta distribution and
for the combination weight in the BC1 model and in the first component of the BC2 model, while the parameters of the second component of BC2 are referred to as
,
and
.
Generally, BC2 models build more flexible predictive cdf: in most of the cases presented, the BC1 models do not take into account the first predictive distribution function (), while BC2 weights more the first one than the second predictive cdf, with few exceptions. Comparing pooling schemes, no clear tendency appears from the tables.
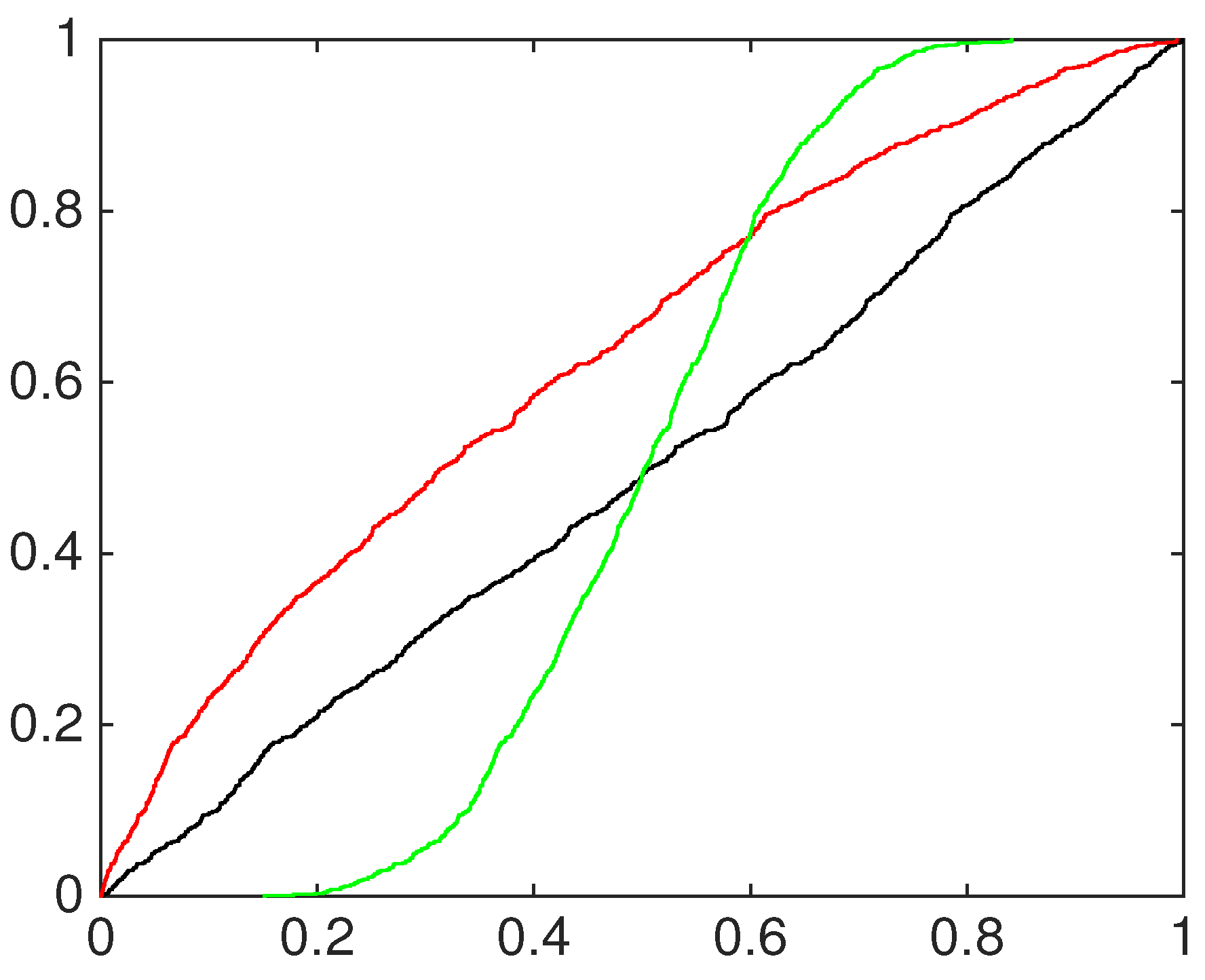
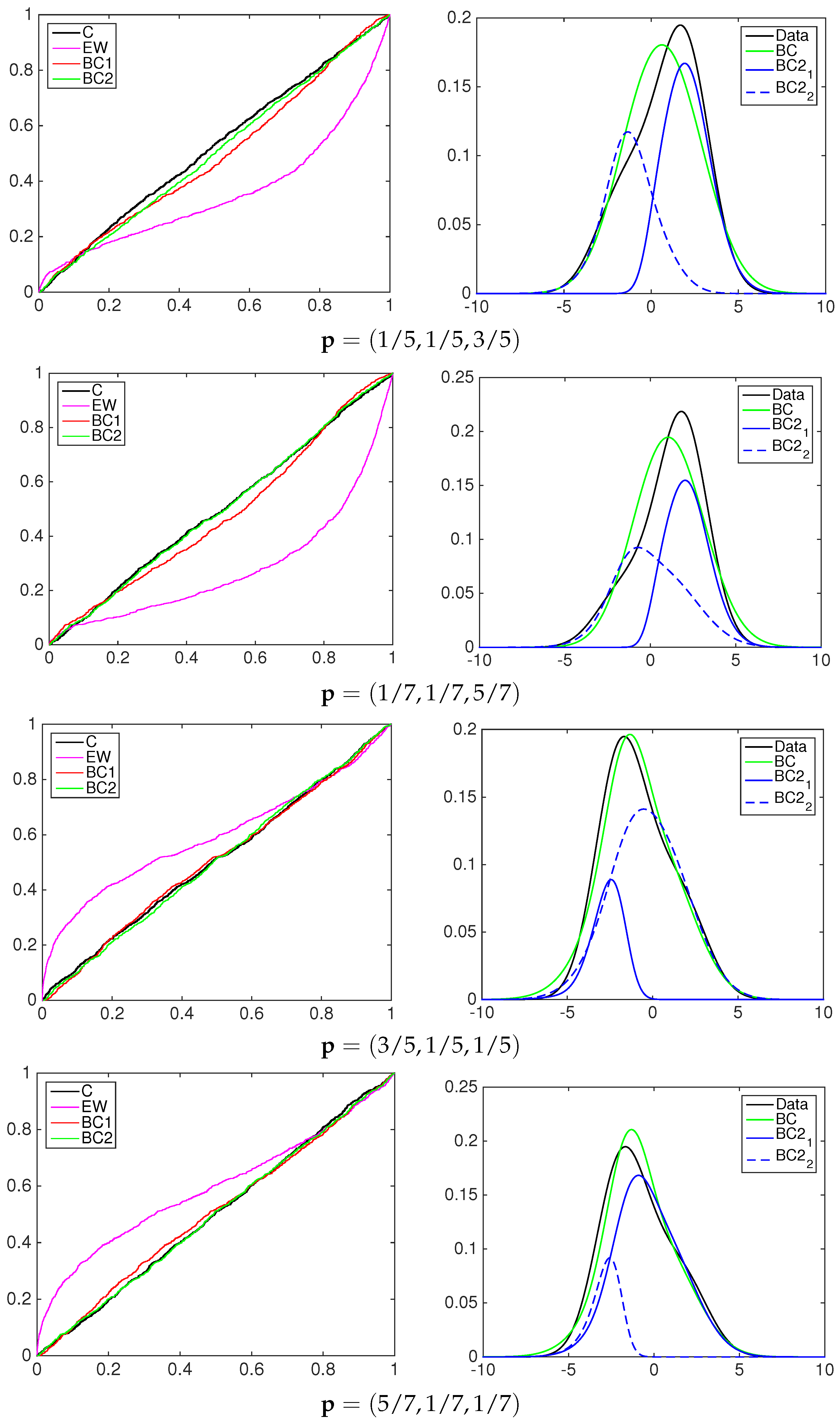
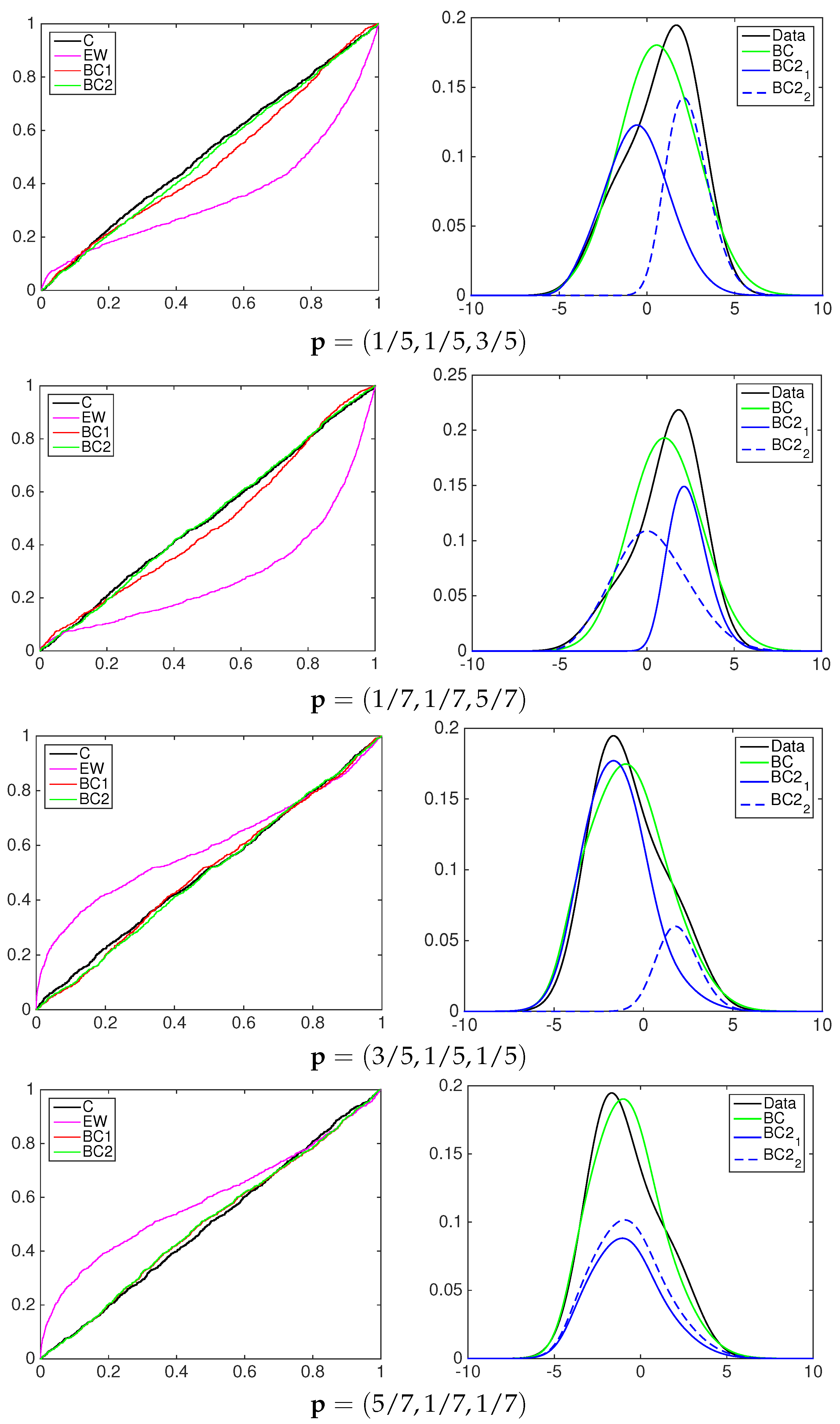
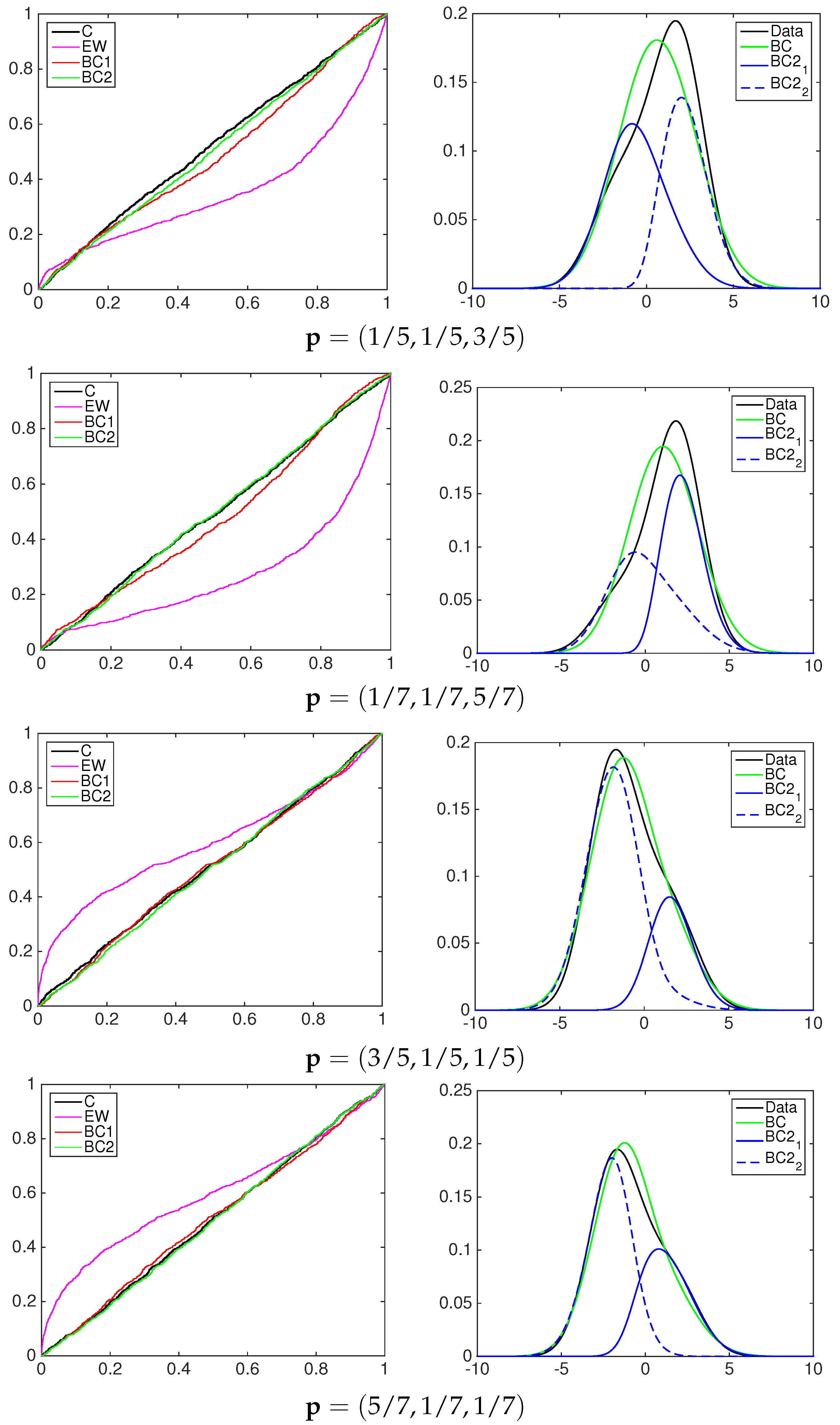
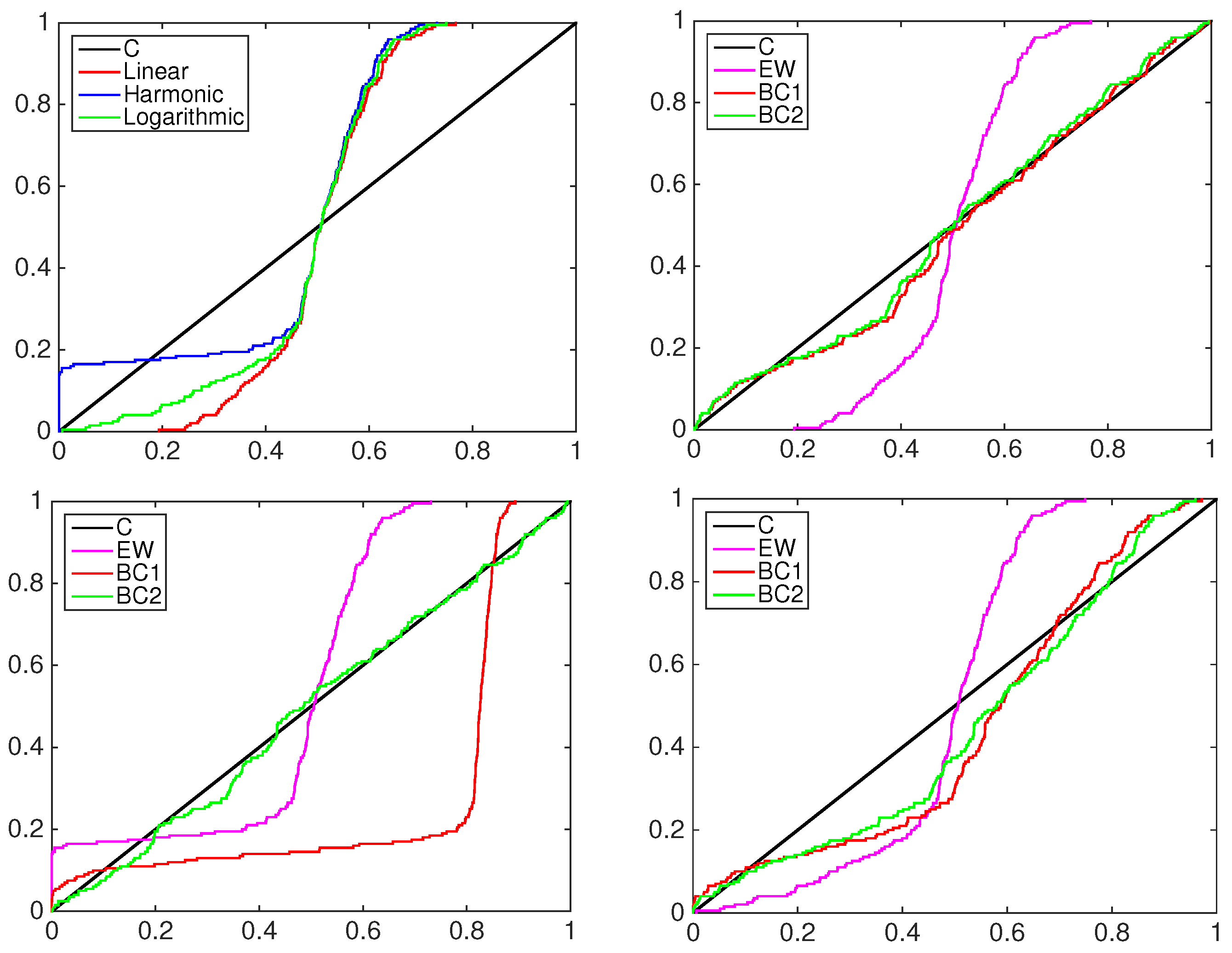
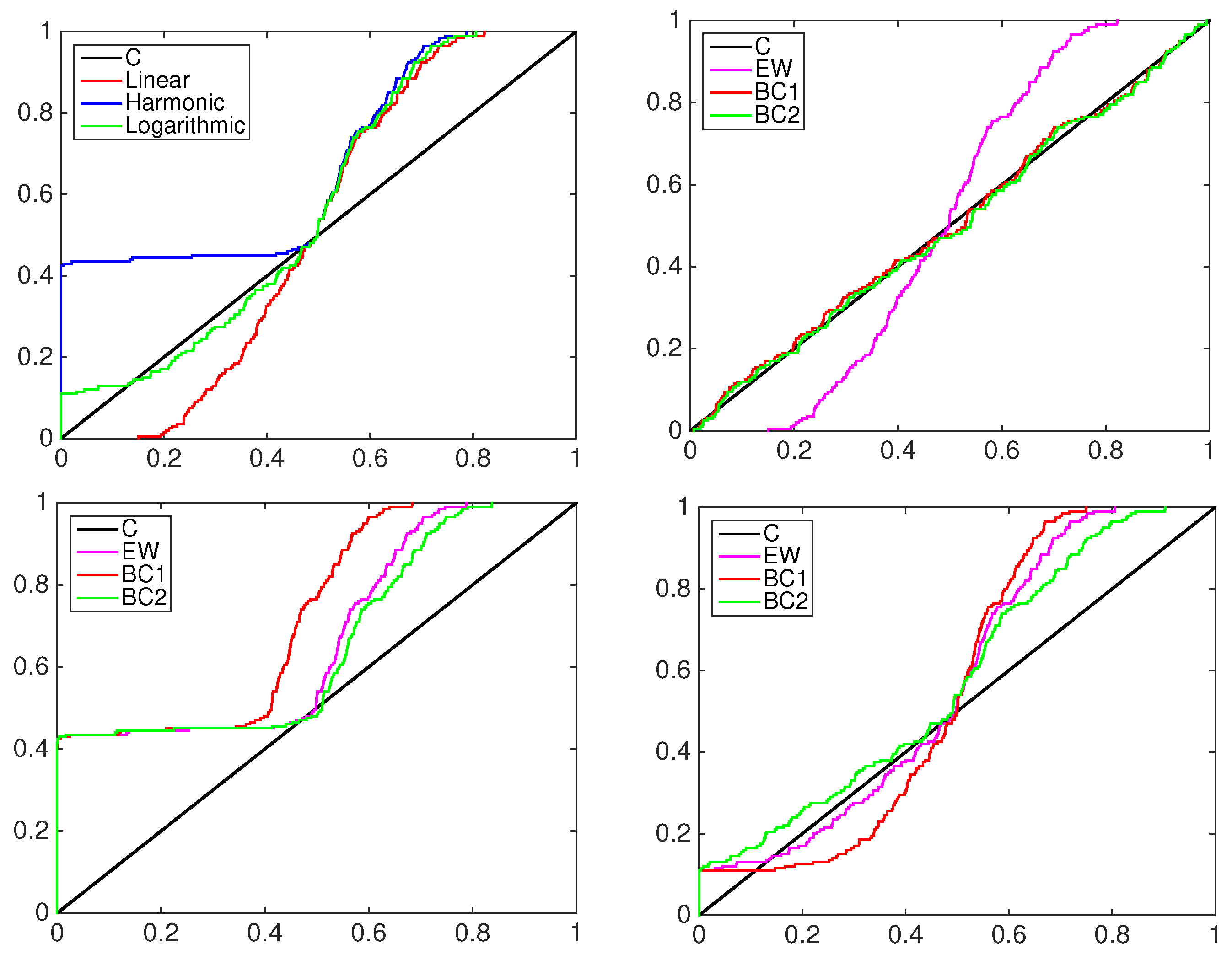
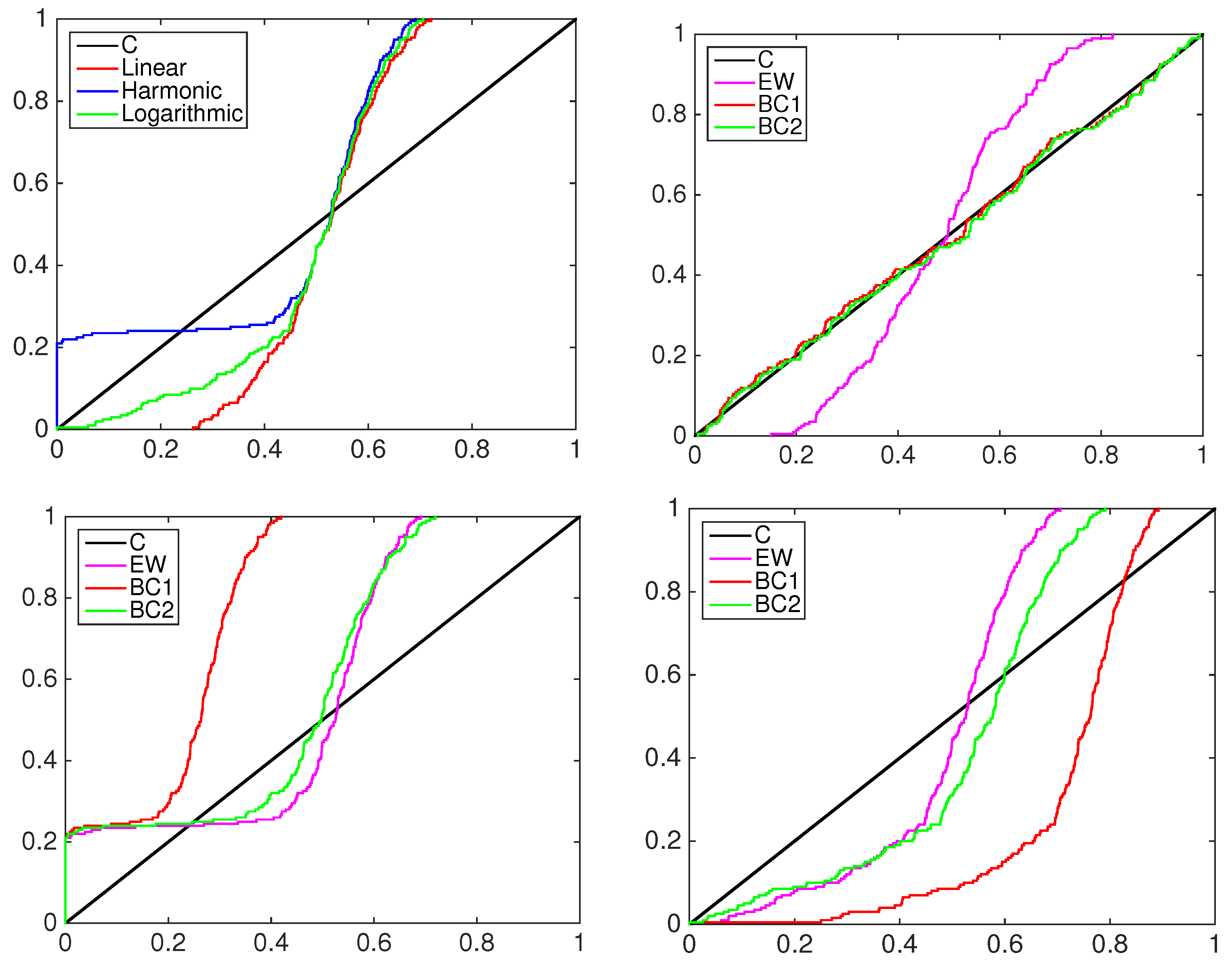
A graphical inspection of PIT cumulative density functions of the three models is proposed to compare them to the simulated data to be predicted; see the left column in
Figure 5,
Figure 6 and
Figure 7. In all of the experiments the PITs of the equally-weighted model (magenta line) lack the ability to predict acceptably the standard uniform cdf of the data simulated by a mixture of normal distributions.
The beta-transformed models (red line) predict the uniformity better than the EQ models, but they overestimate or underestimate the black line mainly in the central part of the support. In all of the pooling schemes used, the beta mixture models provide the closest calibrated cdfs to the uniform one, being able to achieve better flexibility among the others.
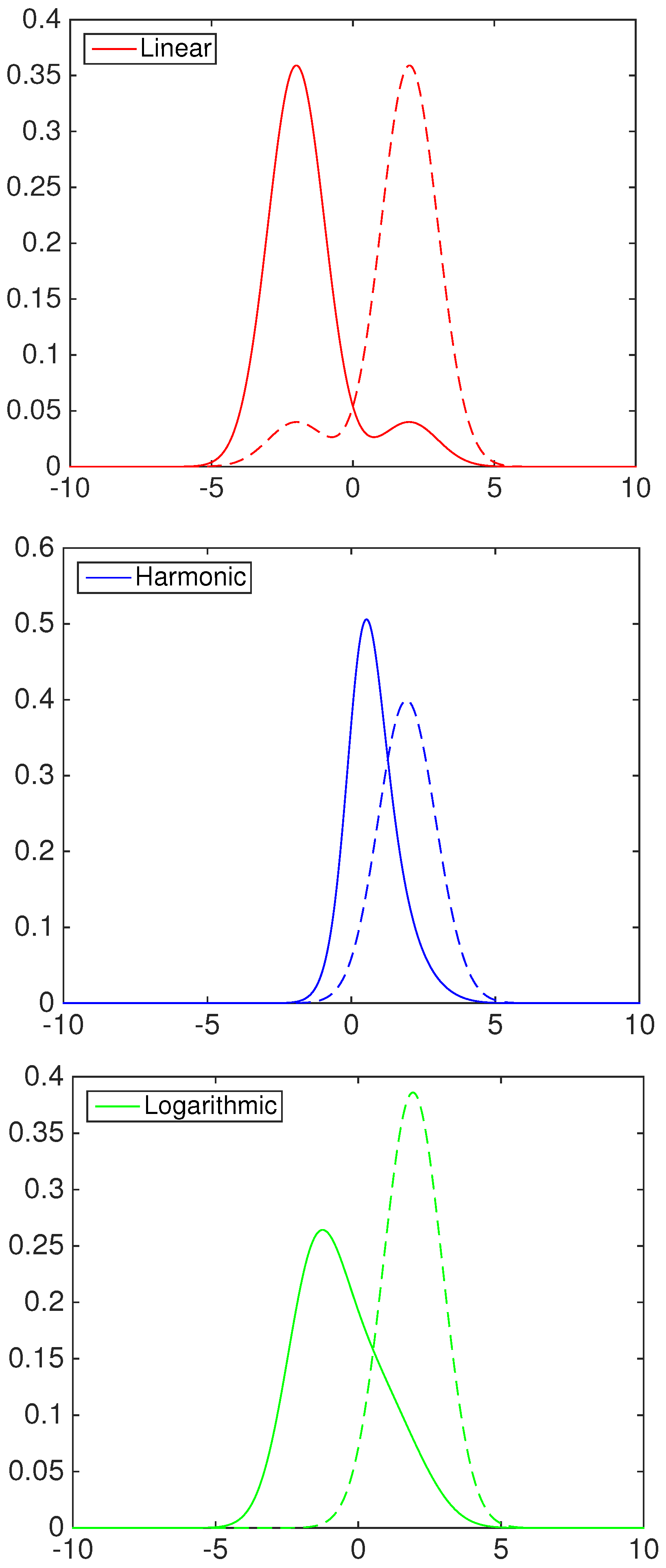
To highlight the behavior of the two-component beta mixture, the right column of
Figure 5,
Figure 6 and
Figure 7 shows the contribution in the calibration process of each element. As an example, consider the first panel in
Figure 5, the BC1 and BC2 models with linear pooling. The solid blue line represents the pdf of the first component of the mixture, the dashed blue line the second component. The multimodality of the data is explained by two predictive functions: the first mixture component, denoted by BC2
, calibrates mainly the predictive density over the positive part of the support; the second mixture component, denoted by BC2
, calibrates the density over the negative part.
Table 1 reports the following values for the weight
ω:
and
. This means that both components weight the first model in the pool more,
i.e.,
.
In conclusion, our simulation exercises find that the result presented in [
19] for the calibration and linear pooling combination of predictive densities is valid for and can be extended to other pooling schemes, including the logarithmic pooling and the harmonic pooling. Moreover, no clear preference for one combination scheme appears from our examples.
4.2. Financial Application: Standard&Poors500 Index
We consider S&P500 daily percent log returns from 1 January 2007–31 December 2009; an updated version of the database used in [
14,
18,
35]. The price series
were constructed assembling data from different sources: the WRDS database; Thompson/Data Stream; the total number of returns in the sample is
. Many investors try to replicate the performance of the S&P500 Index with a set of stocks, not necessarily identical to those included in the index. Casarin
et al. [
21] individuates 3712 stocks quoted in the NYSE and NASDAQ eligible for this purpose, whose 1883 satisfy the control for liquidity (
i.e., each stock has been traded a number of days corresponding to at least 40% of the sample size).
Then, a density forecast for each of the stock prices is produced by the following equations:
where
is the log return of stock
, at day
t;
and
for the normal and
t-Student cases, respectively. Both models produce 784 one day ahead density forecasts from 1 January 2007–31 December 2009 by substituting the maximum likelihood (ML) estimates for the unknown parameters
(for further details, please refer to [
21]).
The major contribution of this technique is the construction of a sequential cluster analysis for our forecasts. The work in [
21] computes two clusters: one for normal GARCH(1,1) models and another one for
t-GARCH(1,1). Then, we obtain a combined forecast of the S&P500 Index combining and calibrating the two classes of predictive distribution functions,
i.e., GARCH(1,1) and
t-GARCH(1,1), through the equally-weighted, the beta-calibrated and the two-component beta mixture models with linear, harmonic and logarithmic pooling schemes.
The clustered weights are assumed to be one and defined by:
where 3766 is the total number of predictive distribution functions: 1883 belonging to the class GARCH(1,1) and 1883 to the class
t-GARCH(1,1). That is, the combination model gives weight
to the class of GARCH(1,1) (first 1883 models) and
to the class of
t-GARCH(1,1) (second 1883 models). The stage is open to further extensions, suggesting a less restricting weighting system.
The period taken into account is particularly interesting because it includes the U.S. financial crisis. Our analysis considers three subsamples, of 200 observations each, representing three periods with different features. The time from 1 January 2007–5 October 2007 is defined as a tranquil period, and the predictability of the index could be hypothesized better than the one from 20 June 2008–26 March 2009 during which the financial crisis developed: here, one can expect that the high volatility makes it more difficult to predict the returns. Finally, the third subsample includes data from 27 March 2009–31 December 2009, the post-crisis period. We aim to inquire if some difficulties in the forecastability and forecast calibration are still present in the post-crisis period. The two classes of predictive density functions, GARCH(1,1) and t-GARCH(1,1), are combined and calibrated through the following models: the equally-weighted (EW) model, the beta-calibrated (BC1) model and the two mixture beta-calibrated (BC2) model. For each model, the three combination schemes are considered: linear, harmonic and logarithmic.
The sequential estimation and combination of the models have been conducted on a cluster multiprocessor system, which consists of four nodes; each comprises four Xeon E5-4610 v2 2.3-GHz CPUs, with eight cores, 256 GB ECC PC3-12800R RAM, Ethernet 10 Gbit and 20-TB hard disk system with Linux. The code has been implemented in MATLAB (see [
36]), and the parallel computing makes use of the MATLAB parallel computing toolbox. The parallel implementation of the sequential estimation exercise allows us to obtain the results in 36 hours with a computational gain of the parallel over the sequential implementation of 120 hours.
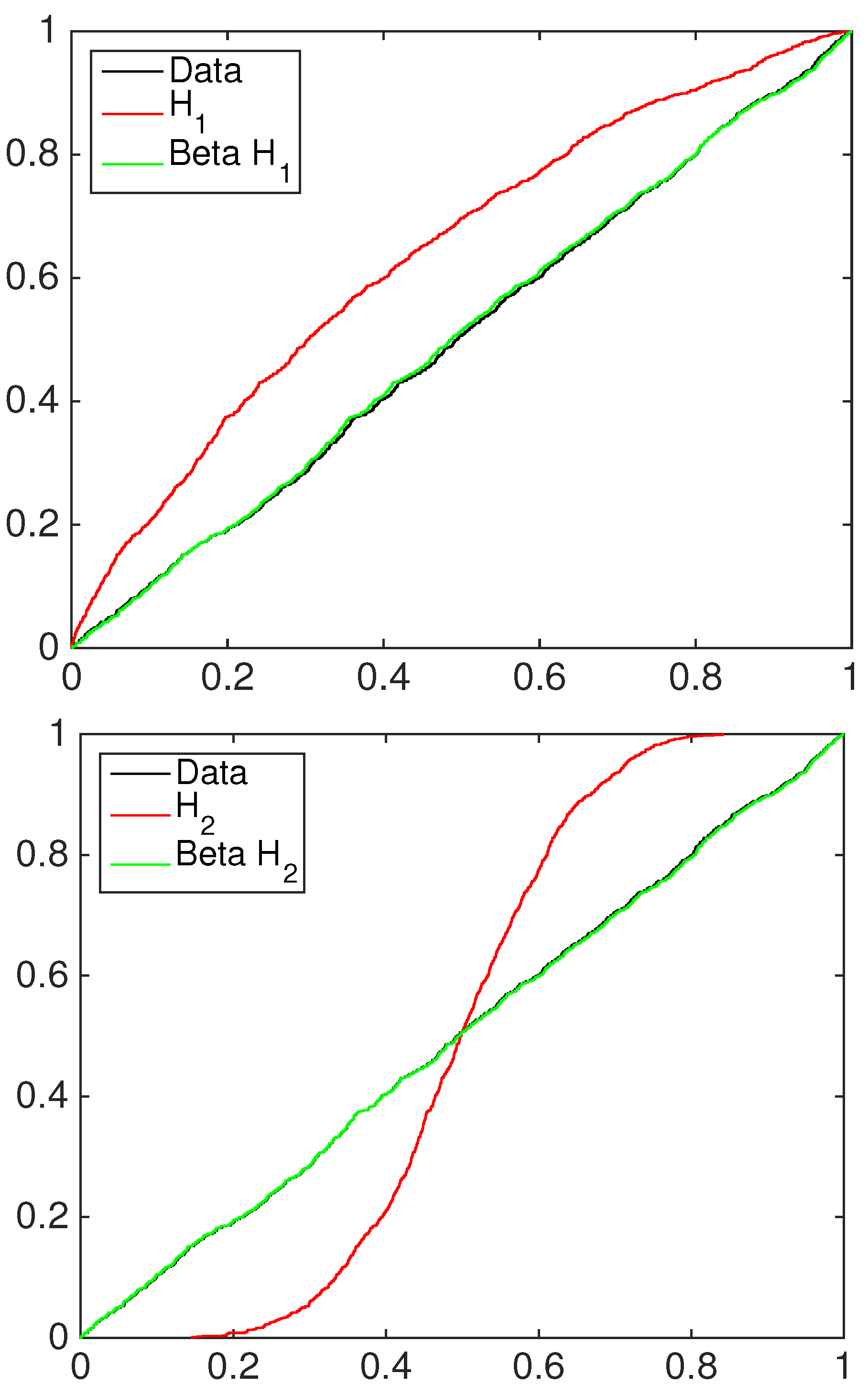
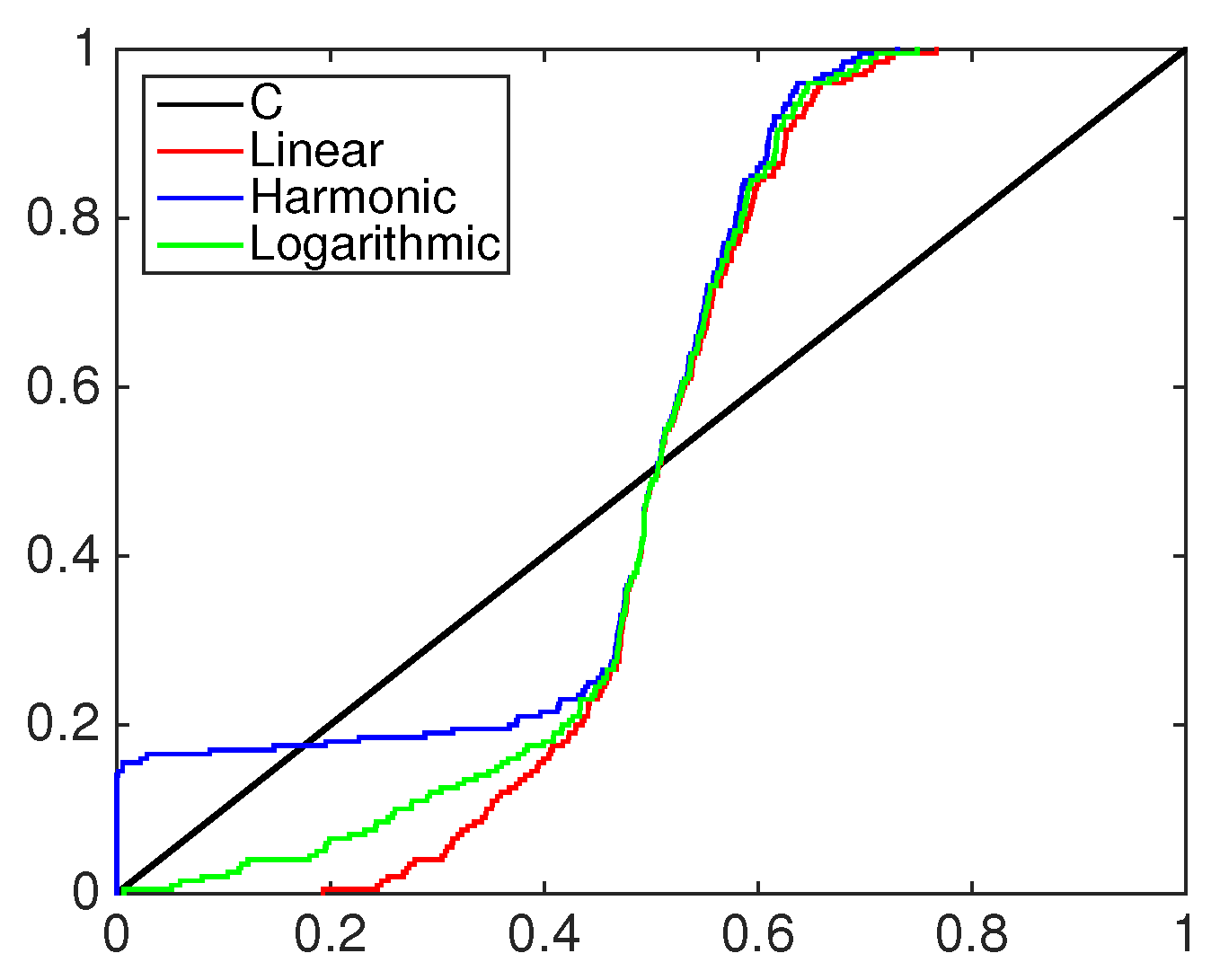
Figure 8 displays a comparison through PITs of linear, harmonic and logarithmic pools when those are combined with the equally-weighted model and the 45 degree line, which represents the PITs for the unknown ideal model. Linear, harmonic and logarithmic pools have the same behavior in the center part of the support; the differences among them are mainly in the tails, in particular in the left one. With respect to the linear and logarithmic scheme, indeed, the harmonic pool (blue line) underestimates more often the frequency of the observations in the tails. The scheme closer to the 45 degree line is the harmonic one, thanks to its better performance in predicting tail events.
For the first 200 days, from 1 January 2007–10 October 2007, where the volatility is roughly the same, the posterior means of the BC1 and BC2 parameters (represented by the vector
θ) are reported in
Table 4,
Table 5 and
Table 6. Here,
and
stand for the parameters of the beta distribution in the estimated BC1 model and in the first component of the BC2 model, while the second component of BC2 is referred to as
and
.
In all of the cases presented, the estimated BC1 models give zero weight to the class of
t-GARCH(1,1) models, as well as the fist component of the beta mixture (BC2); while the second component of the BC2 in the harmonic and logarithmic cases weights the class of
t-GARCH(1,1) models more than the class of GARCH(1,1) models. To better understand the effect of these parameter estimates, a graphical inspection of PITs is reported in
Figure 9,
Figure 10 and
Figure 11, for the pre-crisis, in-crisis and post-crisis period respectively.
In all examples, the equally-weighted model (magenta line) lacks the ability to predict acceptably the ideal standard uniform cdf; see
Figure 9,
Figure 10 and
Figure 11. Just in one case, the linear one, both BC1 and BC2 perform well, providing the closest calibration to the uniform one, being able to achieve better flexibility for all of the time periods analyzed. In the harmonic and logarithmic cases, the BC1 model lacks the ability to calibrate the class of GARCH(1,1) and the class of
t-GARCH(1,1) models, fitting even worsen than the equal weight model. However, a satisfactory calibration is obtained by the BC2 model, even if not as good as that achieved by the linear pool. This is confirmed for all if the periods in our sample, even if the PITs’ calibration gets worse in the crisis and post-crisis phases, highlighting some difficulties in being flexible. However, the linear pooling achieves good calibrated forecasts in both beta combination models; if the pool employed is chosen among the harmonic and the logarithmic schemes, satisfactory results are provided by the two-component beta mixture model.
In conclusion, we prove that the result in [
19] for the beta mixture calibration and linear combination of predictive densities is still valid when harmonic and logarithmic combination schemes are applied.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}