1. Introduction
In the last decade, we witnessed a growing interest in the spatio-temporal characterization of ocean wave fields. Indeed, many complex phenomena are now accounted for (and better described) by leveraging the traditional one-point observation systems (like buoy, wave probes, etc.) to its spatial extent. To cite a few recent examples, Benetazzo et al. [
1,
2,
3] showed that classical point-based models were unsuitable to predict the likelihood, shape, and height of rogue waves over an area. Filipot et al. [
4] studied extreme breaking waves and their mechanical loading on heritage offshore lighthouses, Stringari et al. [
5] developed a probabilistic wave breaking model for wind-generated waves, and Douglas et al. [
6] analyzed wave interactions against rubble mound breakwaters.
Usually, acquisition of such data are made with a remote sensing infrastructure comprising different sensors and computational techniques according to the desired scale and resolution. The range of application spans from millimeter wavelength, exploiting the reflected light polarization [
7], to a hundred meters where X-band radars are typically used [
8,
9]. At a medium scale (from
to 50 m wavelength), optical systems based on stereo vision have proven to be particularly successful as they directly sample the three-dimensional sea surface over time [
10,
11,
12,
13]. However, the high accuracy and resolution of stereo approaches come at a price of a quite demanding computing power. Indeed, they are typically used to acquire few interesting sequences (usually shorter than one hour) that are processed later on for analysis [
14]. It is worth being noted that most of the resources are spent to fit an equi-spaced surface grid (required for the Fast Fourier Transform) out of the scattered point cloud that exhibits a non-uniform spatial density caused by the perspective distortion.
Recently, we proposed a new approach called WASSfast [
15] with the objective of producing 3D surfaces in a (quasi) real-time fashion. The reason is not just a matter of efficiency: producing wave-fields on-the-fly with image acquisition can potentially lead to a system able to run continuously and unattended, generating valuable sea-state statistics over long periods. Albeit promising, WASSfast can produce surfaces of
points at ≈1 Hz, which is a huge improvement against traditional methods [
12] but not yet suitable for continuous operation.
Inspired by the recent advancements in Deep Learning models, we started investigating the feasibility of a fully data-driven Machine Learning approach for the estimation of wave surfaces from stereo data. As a matter of fact, our task shares many similarities of typical inverse problems in imaging [
16,
17] for which ML represents a viable solution. Indeed, it is trivial to sample a sparse set of 3D points from a continuous surface (direct problem) but the inverse is in general ill-posed. Thus, it makes sense to use the direct problem to generate the data needed to train a model created to solve the inverse.
In this paper, we introduce a novel Convolutional Neural Network (CNN) designed to be plugged into WASSfast as a replacement of the FFT-based Predict-Update step (WASSfast PU mode from now on). Such network is trained on simulated wave fields to learn how to produce accurate surfaces from sparse scattered 3D point clouds. With respect to other CNNs designed for similar tasks, we embed prior knowledge on the wave physics (i.e., the dispersion relation) into the architecture itself. This way, the model can learn quickly and more accurately to reconstruct physically consistent surfaces that can match, or even outperform, the ones generated with previous (i.e., algorithm-based) approaches. Our experiments show the ability of the proposed CNN to estimate reliable wave fields (on grids of points) at a fraction of time of the WASSfast PU algorithm, and with a more even noise distribution in the directional wave spectrum.
Related Work
First attempts to create remote sensing systems to measure sea waves with stereo imaging trace back to the late eighties, with the pioneering work of Shemding et al. [
18,
19] and Banner et al. [
20]. However, at that time, computing power was limited and most of the analysis was conducted manually on just a few significant frames. It was only about a decade later that Computer Vision scientists devoted their interest in developing new techniques to automatically recover depth information from single, stereo or multi-view images. In particular, a whole class of algorithms called
Dense Stereo have been actively studied to infer the disparity (and consequently the depth) of each pixel in a stereo image pair [
21]. Such advancements have been gradually used for oceanographic studies, like in the seminal works of Benetazzo et al. [
22], Wanek et al. [
23], and Gallego et al. [
24,
25].
In 2017, Bergamasco et al. published WASS [
12], an open-source software package using state-of-the-art stereo techniques to automate the process of computing a dense point cloud from stereo pairs. It has gradually become popular for many research teams worldwide, to study waves both in open sea [
1,
14,
26,
27,
28] or laboratory wave tanks [
29,
30]. Recently, such techniques have been improved following two main research directions. The first is driven by the need to reconstruct wave fields without assuming that the cameras are fixed with respect to the sea surface. This would allow the installation of such system on oceanographic or general purpose vessels. Significant improvements in this area include the work of Bergamasco et al. [
31] and Schwendeman et Thomson [
32]. The second research direction deals with the stereo reconstruction speed, with the aim of creating wave sensing instruments that can operate continuously and unattended. In this respect, WASSfast [
15] represents a significant step in that direction, even if it is still in a prototype stage.
With the advent of new techniques using Graphical Processing Units (GPU) for model training and inference, machine learning has increased its popularity in many engineering and scientific disciplines. In particular, Deep Learning models now represent the state-of-the-art for many classical Computer Vision problems. In addition, dense stereo has been formulated as a data-driven learning problem, with approaches that can often exceed the accuracy of legacy algorithm based solutions [
33]. In our case, however, most of the time is spent to fit a uniform surface grid to the point cloud, a problem that still needs to also be addressed for deep-learning based dense stereo techniques.
The concept of interpolating and extrapolating scattered scalar fields is ubiquitous in many scientific fields [
34]. In addition, here, many recent approaches are based on Deep Learning, especially when a consistent set of input–output samples are available. In the literature, the general name of “depth completion” refers to the task of recovering dense depth maps from sparse sample points (for example, acquired with LIDARs or Z-cam devices). This is exactly the scenario faced by WASSfast, in which a smooth continuous surface must be estimated from a sparse 3D point cloud. Since the geometry of the scene is known (in particular, the mean sea-plane is already calibrated), the problem can be formulated in the 2D space encompassed by the regular surface grid to be estimated. Directly applying a generic CNN architecture to this problem is not trivial since, for its sparsity, only a fraction of the input layer contains valid data. For this reason, it is not clear how the convolution operator should behave when the filter encompasses a region in which some of the values are not available.
Some approaches tackle the problem by assigning a predefined value to the missing elements [
35]. For example, [
36] fills the input image with zeros to substitute the missing data and then uses classical convolutional layers to propagate the depth information from the existing values. The problem is that choosing an arbitrary value introduces some bias in the solution, like reducing the accuracy of estimation for small depths. To alleviate this problem, [
37] proposed to keep track of the location of the missing values by creating a binary mask of the input data. This mask is then provided to the network as part of the input and convolved with the original data as usual. Nevertheless, this approach does not explicitly limit the convolution to valid data which can still consider arbitrarily chosen fill values.
Recently, Uhrig et al. [
38] proposed Sparse-CNN, a sparsity invariant CNN with a custom convolution operator which explicitly weights the elements of the convolution kernel according to the validity of the input pixels. Furthermore, Huang et al. [
39] refined that concept in their HMS-Net, a hierarchical multi-scale version of the Sparse-CNN to handle data with different densities. Some other approaches simulate different densities in input images to train an encoder–decoder network and make it sparsity-invariant [
40]. In our specific case, we do not observe large variations in the point density, but we suffer from image regions in which data are simply not available (for instance, the occluded back side of the waves, white-capped regions, etc). Thus, our efforts are oriented toward solutions preserving the details where points are abundant, and properly filling the holes in problematic regions.
Finally, latest works in this area aim at improving the reconstruction accuracy by fusing depth data with an associated RGB image [
41,
42]. In our case, the radiance of sea water depends on daylight and meteorological conditions, so it would be impractical to create a training set comprising a reasonable amount of real-world working conditions.
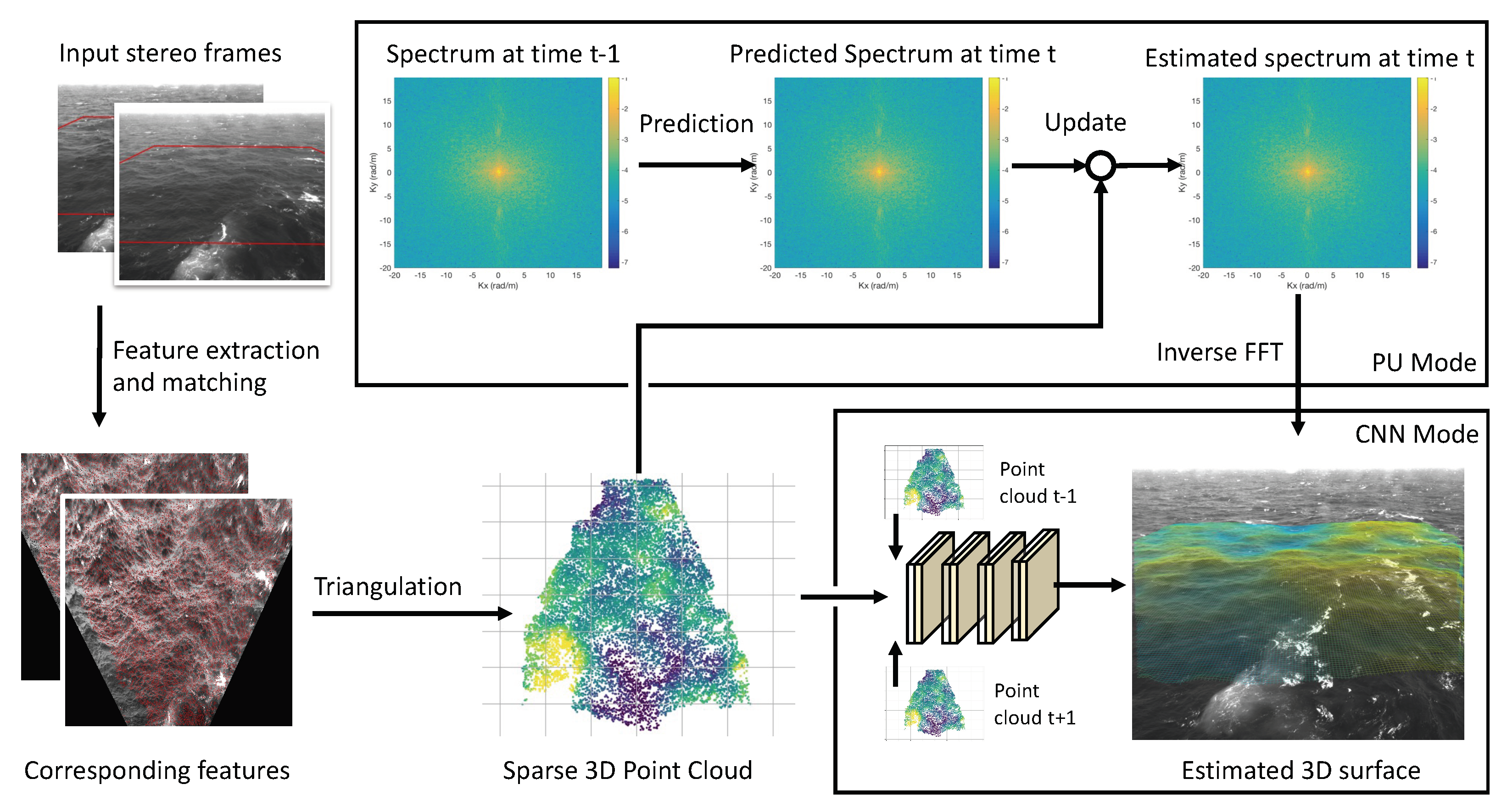
2. WASSfast CNN
WASSfast produces a sequence of 3D wave surfaces from samples obtained by triangulating reliable sets of corresponding feature points that are assimilated frame-by-frame into a continuous surface. We kept the first part (from stereo frames to sparse point clouds) exactly as described in [
15]. Instead, we modified the surface estimation part with a specialized CNN designed to directly interpolate the missing data. Before the in-depth explanation of the new approach, we think it is useful to recap how the whole WASSfast technique works. We refer the reader to the original paper [
15] for more details.
2.1. The WASSfast Pipeline
WASSfast can work efficiently by limiting the amount 3D points triangulated from each stereo pair. To make a comparison, methods based on dense-stereo algorithms [
12] usually produce ≈3 millions points when operating on 5 M pixel images. On the contrary, WASSfast extracts 7000 points on average, which is 450 times less. Assuming that surfaces are described by grids of
points (≈65,000 points in total), the problem is clearly under-determined. In the original WASSfast PU formulation, the ill-posedness is solved by constraining the wavenumber spectrum of subsequent surfaces to loosely behave according to the linear dispersion relation.
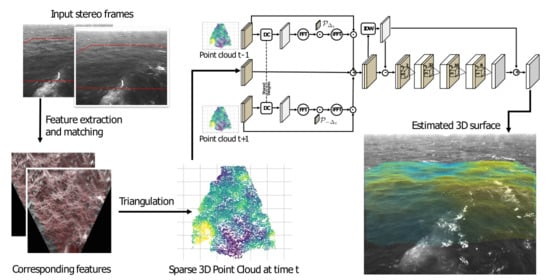
The whole procedure is summarized in
Figure 1. WASSfast operates sequentially on the stereo frames according to their acquisition time. In every iteration, it takes as input the stereo pair at time
t together with the estimate of the surface spectrum at time
(in the first frame, the previous spectrum is assumed to be zero everywhere). Then, the PU approach operates as follows:
feature detection and optical flow are used to extract a set of matching feature points between left and right images;
matches are triangulated to obtain a sparse 3D point cloud;
spectrum at time (i.e., the current frame) is Predicted from the previous estimate at time according to the linear dispersion relation;
spectrum prediction is updated to fit the triangulated points obtained in step 2. This creates an estimate of the spectrum at time that is used when processing frames at time . Thus, the process repeats from step 1.
Considering the obtainable speedup, PU formulation works surprisingly well but contains some intrinsic limitations hindering any further improvement. First, it must process frames sequentially, so no parallel computation can be performed (at least at a frame level). Second, spectrum prediction can only look at the past (previous estimate at time ) and not the future frames. Using both previous and next frames would probably constrain it better for an improved prediction. Finally, the update step is based on a numerical optimization whose running time depends on the data. Convergence can be quick in some cases (just a few iterations) or very slow in some unlucky circumstances. In practice, the maximum number of iterations can be set by the user, but this will not guarantee the convergence. Thus, on average, the processing speed is 1 Hz, but some frames can take longer than others.
The idea explored in this paper is to substitute steps 3 and 4 with a Convolutional Neural Network trained to directly produce surface grids from the triangulated points. The ill-posedness here is solved by letting the model learn what a physically consistent surface should look like according to what has been seen during the training process. The temporal constraints given by the dispersion relation are embedded in the model by processing 3 frames at once: , and to produce the surface at time . When operating on the whole sequence, each frame is partially processed three times (as previous, next and current frame) but, apart from that, model execution can be parallelized on the whole sequence. We call this new mode of operation WASSfast CNN.
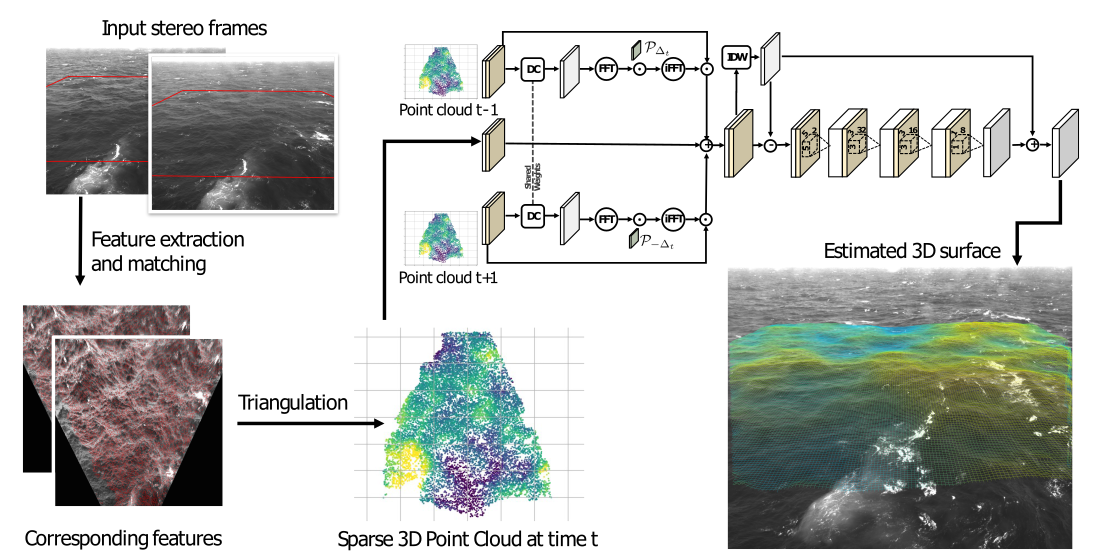
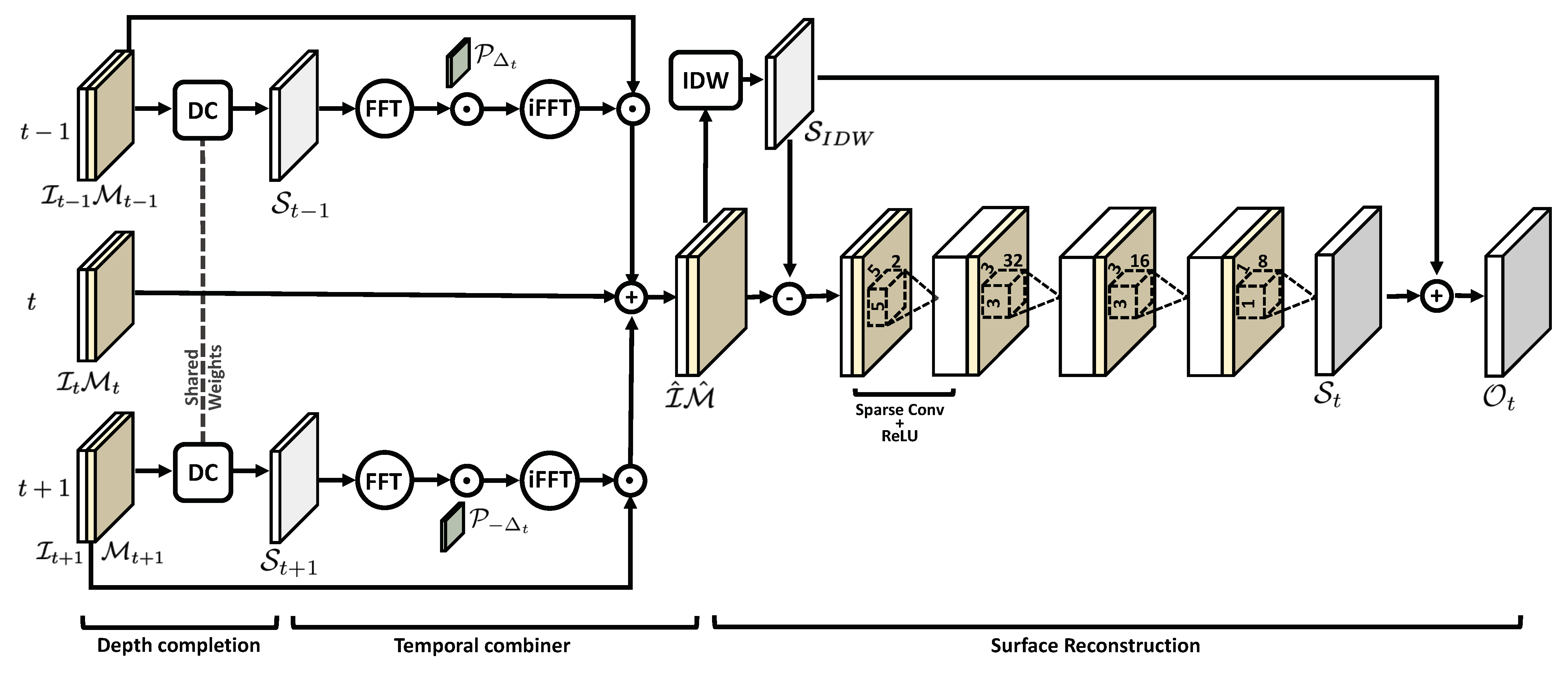
2.2. Network Architecture
Differently from the PU approach, all the triangulated 3D points are discretized to the defined surface grid before any other operation (
Figure 2). This is performed by transforming the point cloud in the mean sea plane reference frame (aligned with the grid), and then projecting each point onto the closest grid node. This operation is implemented simply by discarding the
z-coordinate, and rounding the remaining two to the closest integer. This way, the projection is very fast but less accurate compared to the PU approach for two reasons. First, more than one point can end up into the same grid cell. In this case, we just randomly select one of those and discard the others. Second, some information is lost during the discretization since the original “sub-pixel” coordinates are rounded to the closest grid node. This can lead to a cutoff in the high frequencies of the wave spectrum, unless the grid resolution is reasonably high. Nevertheless, this operation is extremely fast, since it can be parallelized with respect to the point cloud, and automatically solves the problem of having two or more points too close together, a critical condition for the convergence of the PU approach.
After point discretization, the problem is simplified from a general 3D surface interpolation to an image processing-based depth completion performed directly on the surface grid. Indeed, our grid can be seen as a 1-channel floating-point image in which each pixel (i.e., cell) denotes either the elevation of the chosen point with respect to the sea plane or a NaN to indicate that no point was discretized into that grid cell. At this point, the task is to “fill” the missing pixels with reasonable values according to the optimal surface we aim to estimate.
The complete network architecture is displayed in
Figure 3. It takes as input three subsequent frames:
, and produces in output the resulting surface
where the missing values have been filled. It is composed by three macro blocks that are executed one after the other. The
Depth Completion block implements a preliminary fill of
and
using two instances (with shared weights) of the Depth Completion CNN proposed in [
38]. Then, the
Temporal Combiner “transports” the sparse points from
and
onto
t to produce an intermediate sparse image
which is denser than
. From here, the final
Surface Reconstruction part estimates the missing values combining a sequence of Sparse Convolutions with the classical Shepard interpolation [
43] (also known as Inverse Distance Weighting, or IDW).
The novelty of our approach, compared to just using a general purpose Depth Completion CNN, is twofold. First, we introduce physical constraints our reconstructed surfaces (in this case, the dispersion relation) since we know that points are samples triangulated from a real sea-surface. Second, we train the network to reconstruct the difference (i.e., the high-frequencies) with respect to a surface already interpolated with a general-purpose method. Experimentally, we observed that this leads to better results than directly reconstructing the final surface (see
Section 2.5). In the following sections, we describe each block in detail.
2.3. Depth Completion Block
The depth completion block consists of an end-to-end CNN taking a input tensor and producing a output tensor . The two input channels are organized as follows: the first channel is a floating point image containing some pixels with valid depth values (representing sea-surface elevation at that grid point, normalized in range according to the minimum and maximum value of the batch) and some others corresponding to missing data, arbitrarily filled with zeros. The second channel consists of a data mask, i.e., a binary image containing 1 or 0, denoting respectively that the pixel at that coordinate is valid (i.e., the first channel contains an observed value) or not.
The architecture is a classical feed-forward network as shown in
Figure 4: it contains a sequence of five sparse convolution layers, followed by Rectified Linear Unit (ReLU) activations. Each sparse convolution produces a 16-channels output tensor obtained by convolving the input with 16 different trainable kernels with predefined sizes. At the end, a sparse convolution with a single
kernel followed by a linear activation produces the resulting dense output surface
.
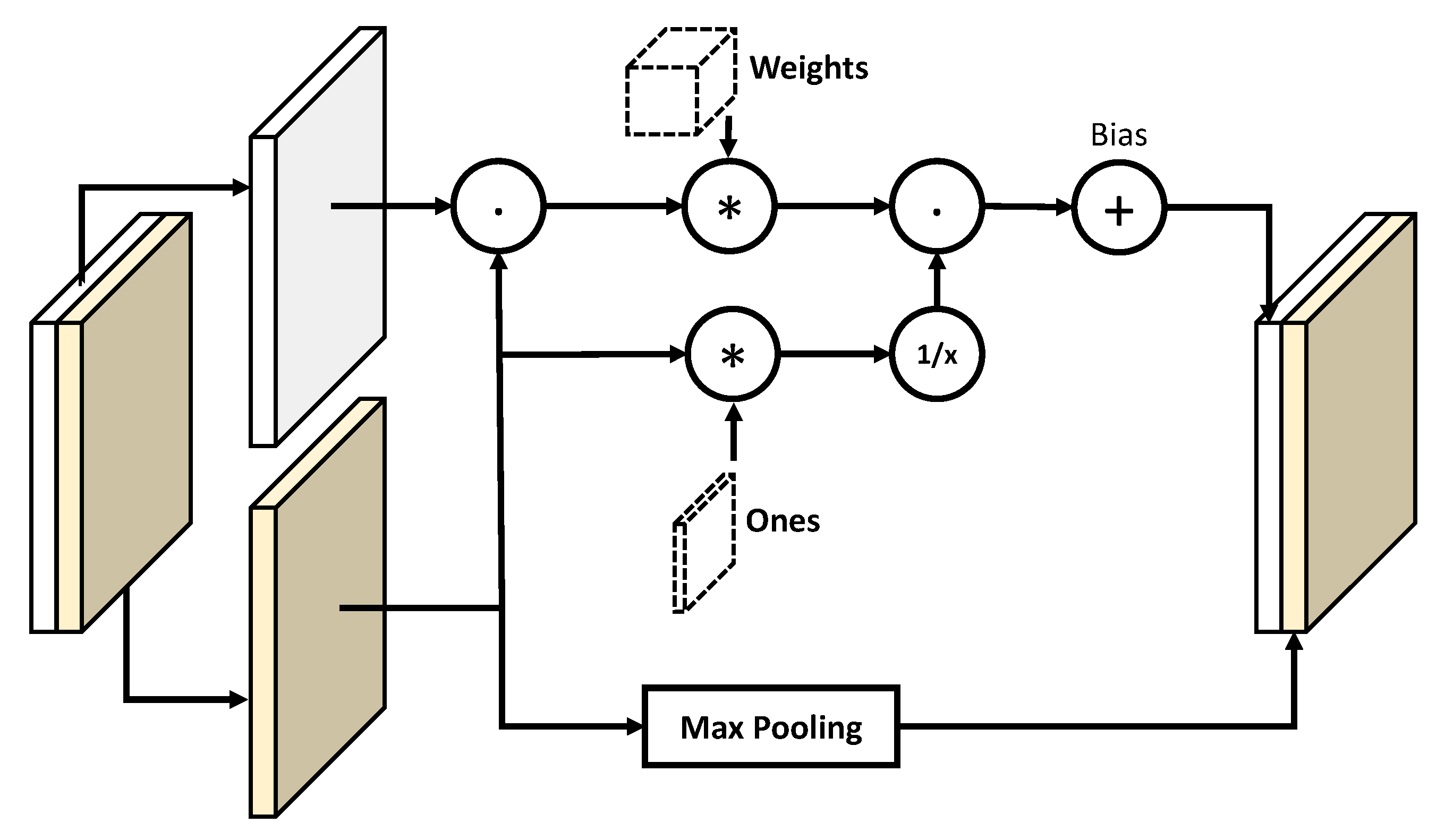
The idea behind sparse convolution is simple but effective in practice. Let the input be a
tensor, composed by the concatenation of a
tensor representing image data and an
tensor representing the binary mask (respectively white and yellow blocks in
Figure 5). The first data block is multiplied element-wise to the mask to explicitly fill invalid values with zeros (note that valid values remain untouched since they are multiplied by 1). The zero-filled data are convolved as usual, but the result is normalized according to the number of valid values inside the region spanned by the convolution filter. In other words, the normalization factor results in being the number of ones found in the mask within the corresponding convolution window: such factor is simply computed by convolving the mask with a constant kernel composed by all ones, with the same size as the kernel used for data convolution. Finally, the layer output is computed by dividing the convolved data with the convolved mask, and then adding a trainable bias.
At the same time, the mask needs to be updated coherently with the new data in order to propagate the information. This is done by dilating the 1-regions of the mask, performing a max-pooling operation with unitary stride and size equal to the convolution kernel (note that this is equivalent to compute a morphological dilation on the mask). In this way, the valid data values are propagated through the new mask. Assuming to employ
v filters for data convolution, the new data and mask are concatenated together to produce the
output tensor. The whole operation is summarized in
Figure 5.
Note that, albeit generic, this block would be sufficient to fill the missing grid values. However, as shown in the experimental section, what follows embeds physical priors to the network and greatly improves the final surface.
2.4. Temporal Combiner Block
The temporal combiner block lies at the core of the proposed WASSfast network: indeed, it is designed to fuse the information coming from three subsequent frames and improve the quality of the final output. The rationale is that each input frame
can be seen as a random sampling of the unknown sea surface at time
t. Therefore, considering two distinct frames
and
, they will contain valid values at different locations. If we imagine to “transport” the valid points from
to
(or vice-versa), we can increase the sampling density of one of the two images and therefore improve the quality of the final output. This operation is not trivial unless we are able to accurately track the reconstructed points along the frame sequence. Nevertheless, physical priors on the wave dynamics can be taken into account to predict the sea surface at a certain (sufficiently small) time delta
. This is exactly the operation performed by the PU approach during the prediction phase (see [
15],
Section 2.3 for details). To summarize, it is sufficient to take the 2D Fourier spectrum of the surface at time
t, rotate its phases by an angle defined by the
linear dispersion relation, and then compute the inverse Fourier transform to obtain the predicted surface at time
.
The structure of the temporal combiner is shown in the central part of
Figure 3: it takes as inputs the previous
, next
and current frame
in the sequence being analyzed, together with their associated masks
,
and
.
The depth completion block described in
Section 2.3 is applied in parallel (sharing the weights) only on
and
. In this way, we obtain the two dense surfaces
and
associated with the previous and next frames, respectively.
At this point, we can exploit the temporal relation between subsequent frames and predict two new surfaces by rotating the phases of
and
, assuming a time delta of
and
, respectively. This is implemented as an element-wise multiplication between the complex matrix resulting after the 2D Fourier transform of the surface and a phase rotation matrix:
where
denotes the 2D Fourier transform and ⊙ is the element-wise matrix multiplication. The 2D phase rotation matrix
is computed as follows:
where
are the grid wavenumbers, and
are two signs related the main wave propagation direction (The predict step implemented in WASSfast is able to automatically estimate
by analyzing the optical flow between the first two frames).
In this way,
and
are the predicted surfaces at time
t computed respectively from
and
. In other words, this operation allowed for “moving” both the surfaces to time
t, enabling us to merge the resulting data with different random samplings. Then,
and
are sparsified again by filling with zeros all the pixels corresponding to zeros in the original binary masks:
The final step of the temporal combiner consists of blending the obtained values and the current input sparse data
. First, the three sparse images need to be combined according to possible overlapping. Indeed, since we want to merge in the same image sparse points coming from different random samplings, we need to take care of the pixels for which we have more than one value. For this reason, given a pixel location
p, the corresponding values will be weighted as follows:
where
is a weighting parameter. In this way, if only one out of three elevation values is present at pixel
p, it will be included in the merged image. On the other hand, if we have more than one possible value in
p, the final elevation is computed as a weighted sum of the available values. In our tests, we gave a higher relevance to the central frame (i.e., the input data for which we did not apply prediction) by setting
. Note that, with this formulation data in
and
being weighted equally, there could be some cases for which they should be treated differently, for example if the frame rate is not constant. Indeed, the adaptation of such weighting parameters could be further investigated in some future work. After the operation described in Equation (
4), the sparse image
incorporates sparse points coming from the three input frames, exploiting the prediction step. The associated mask is simply computed as the element-wise logical or among the three input masks:
Given the different random sampling at each frame, this new sparse image
will be denser with respect to the three inputs taken separately, with the advantage of possibly improving the final surface quality and constraining the temporal evolution of the surfaces according to the data acquired immediately before and after the currently reconstructed frame. Note two interesting features of the temporal combiner. First, the Fourier Transform and point blending are all linear operations that can be easily differentiated so it does not pose any problem for the back-propagation [
44] (Chapter 6.5). Second, the temporal combiner does not contain any weight to be trained. After this part, the pair
is then used as an input for the reconstruction block.
2.5. Surface Reconstruction Block
The surface reconstruction block is added after the temporal combiner, taking as input the sparse data and the mask . At this stage, is denser than the original , but tends to exhibit regions where no samples at all are present. These “holes” in the data typically occur on the back-side (with respect to the camera viewpoint) of high waves or in areas where no photometrically distinctive features are present (like in flat white-capped regions formed by breaking waves).
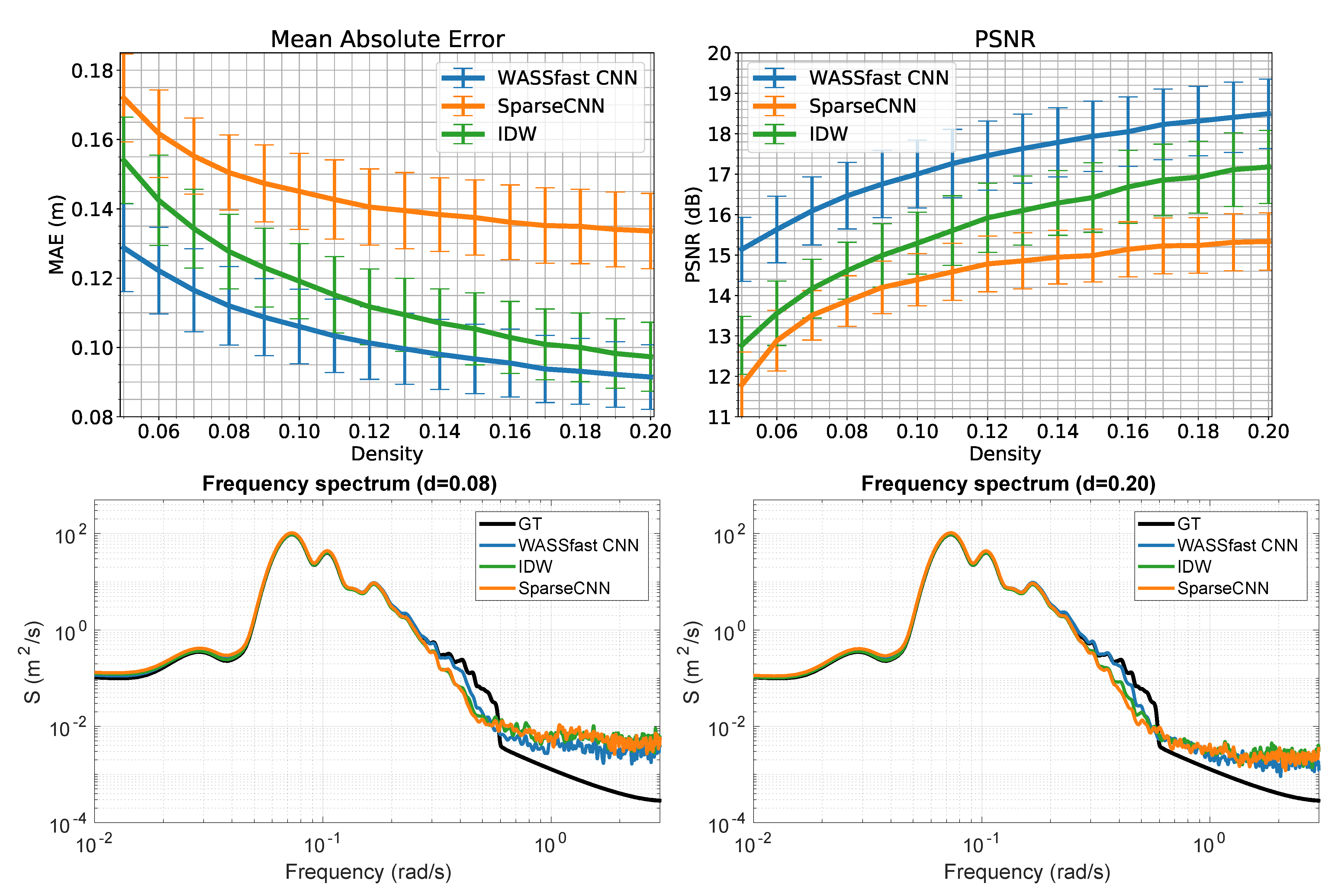
We observed that just using the depth completion block (
Figure 4) fails to both preserve details where many samples are present and close the larger holes. The problem is that the sparse convolutions must have a limited extent (
or
) to be effectively trained, but that means increasing the network depth to accommodate sparser regions. However, in all our tests, we observed that the deeper the network, the smoother the resulting output tends to be. One solution might be to use a multi-scale depth completion network [
39] in this last stage, but such architecture is more complex and therefore harder to train and slower during its usage. Thus, we explored a different approach in which sparse convolutions are used only to improve the surface’s small details.
It is easy to note that the classical Shepard interpolation (in its simple form, without taking into account local gradients) is a non-trainable instance of a sparse convolution (see
Figure 5). In addition, known as Inverse Distance Weighting, the idea is to fill a missing value with the average of the valid neighboring pixels, weighted by a negative power of their distance. If we restrict the averaging neighborhood to a fixed maximum radius, its implementation can be realized by convolving both the sparse data and mask with a kernel filled with values that are proportional to the distance from the central pixel. After that, the convolved image is divided element-wise with the convolved mask to obtain a dense surface. Since the IDW kernel values are not trainable, its impact on our model is negligible even when using window sizes several time bigger than the ones used for sparse convolutions. Thus, we decided to mix the two approaches to take the best of the two worlds.
The idea is to create a coarse surface using IDW, and then “add” the additional details with the usual depth completion network that learns to refine the final surface. Indeed, the obtained surface is initially subtracted from the sparse points (essentially like in a high-pass filter), then a series of four sparse convolutions with ReLU activations are performed on sparse data. Finally, the surface is added back to to obtain the final output surface.
3. Network Training
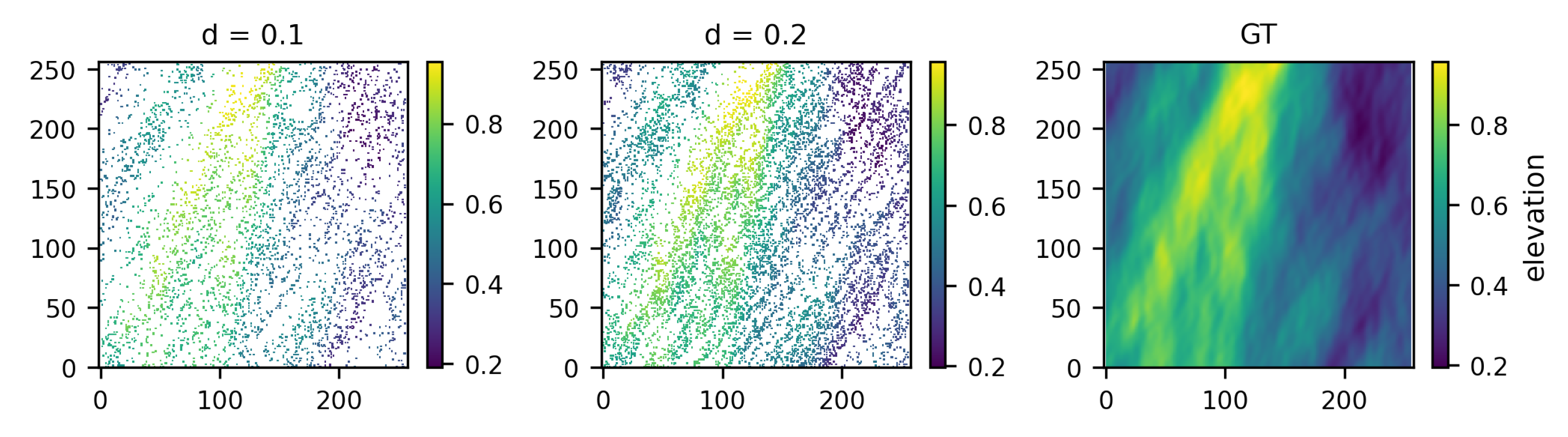
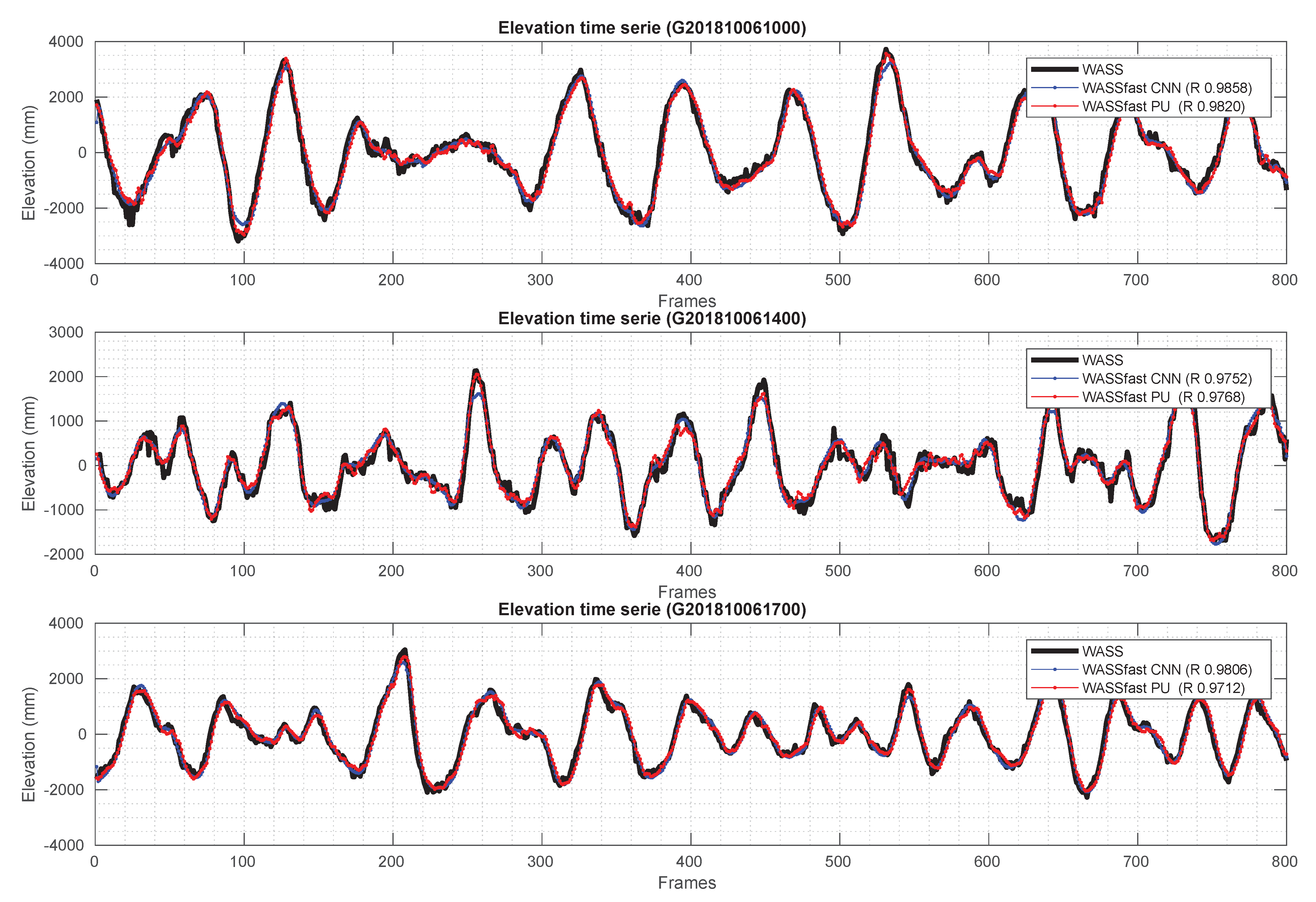
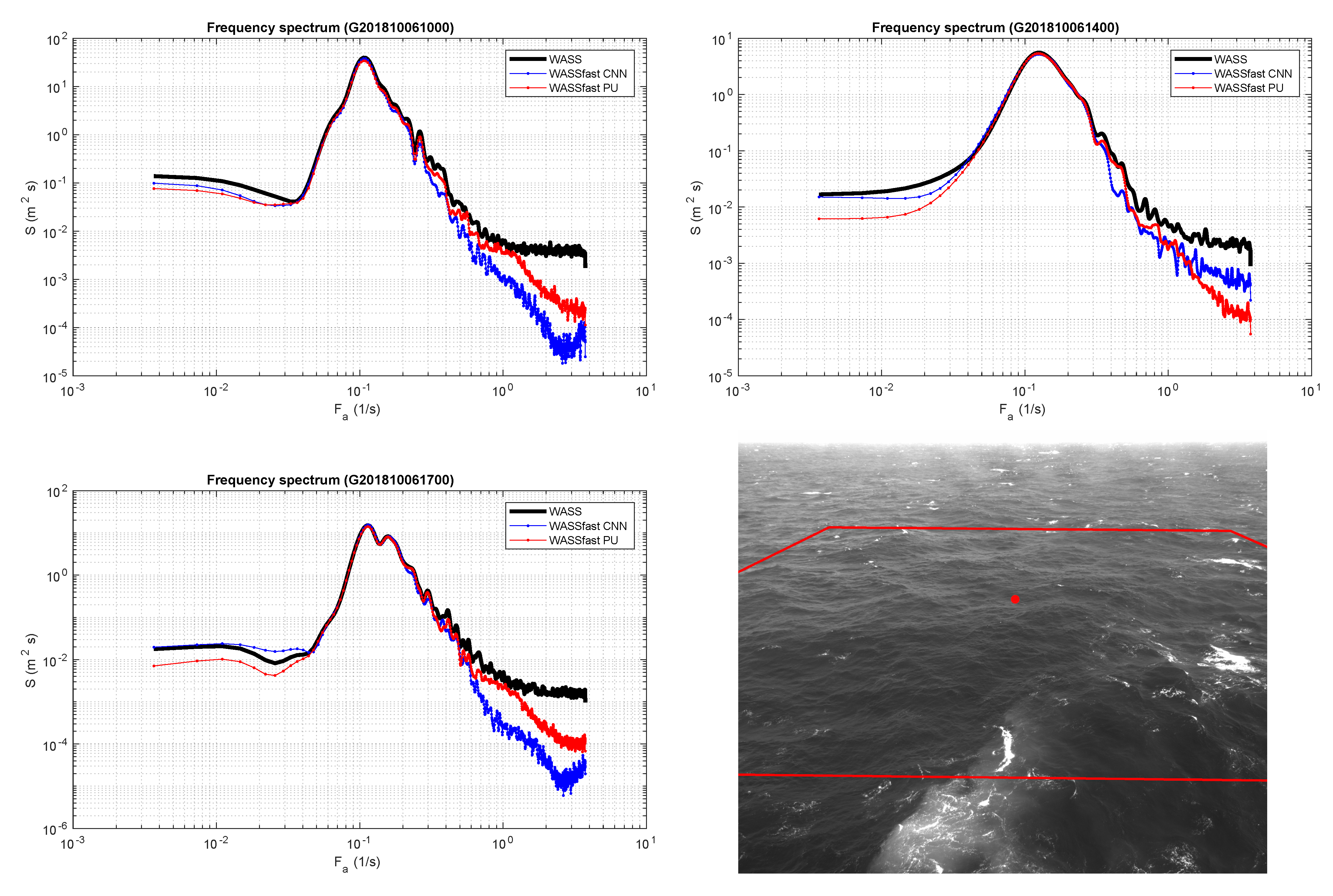
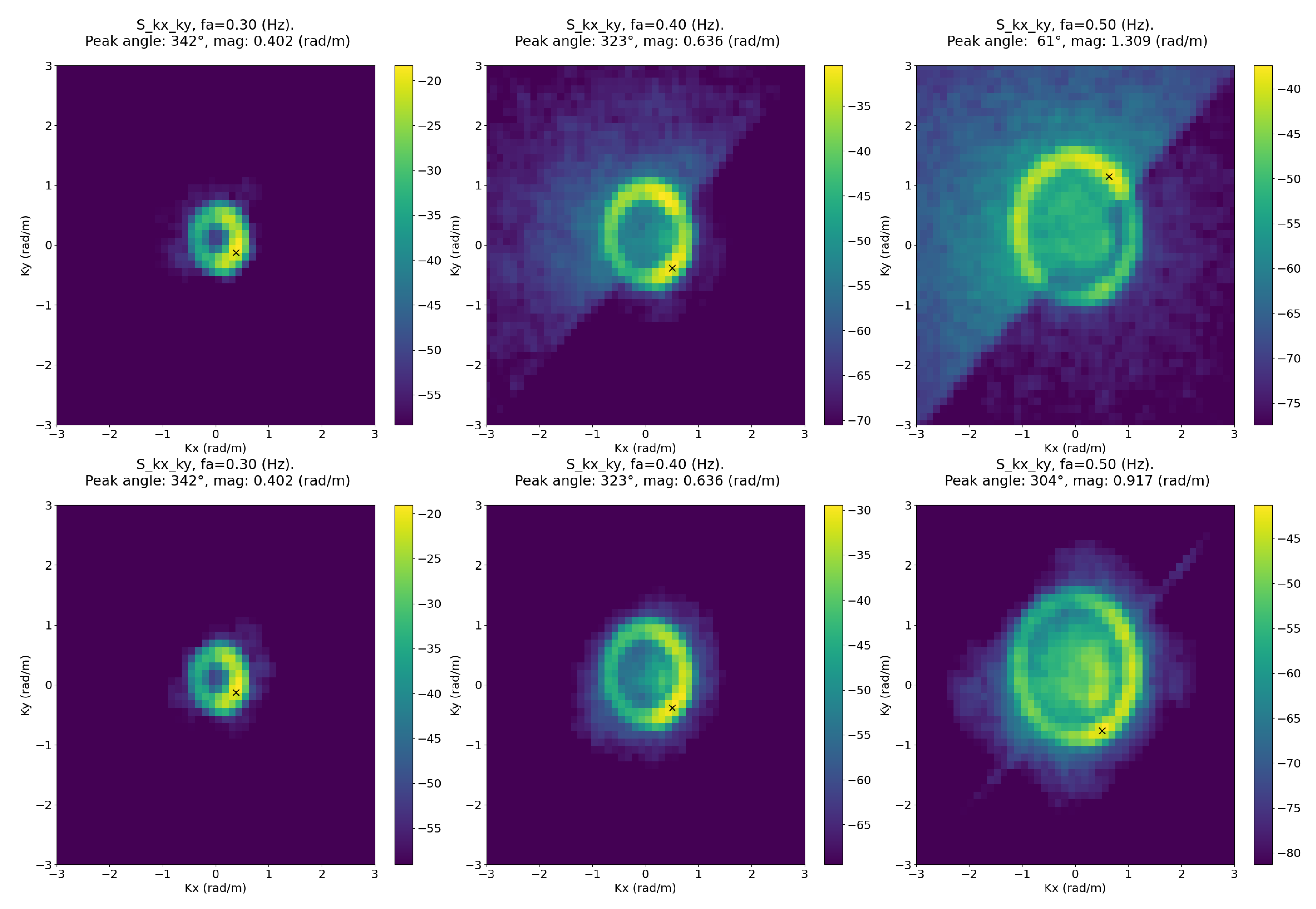
To be properly trained, WASSfast CNN requires several input–output samples, like the ones shown in
Figure 6. One possibility is to use WASS as a reference surface reconstruction method to generate the expected output surfaces. We discarded this alternative for the following reasons:
Training data should be as heterogeneous as possible to comprise different wave direction, sampling density, frame rates, etc. This requires great effort in organizing a vast set of WASS processed data that would be impractical. Moreover, in this way, we are not ensured to capture as many conditions as possible to avoid overfitting.
WASS data partially suffers from depth quantization produced by the dense stereo approach. If used for training data without proper filtering, the CNN would probably learn to “simulate" the quantization effect along the image scanlines;
A vast amount of data needed to train a Deep Neural Network model without overfitting. We currently do not have enough data to ensure proper training, and data augmentation is a partially viable option since it is difficult to define image transformations to realistically simulate different view angles, wave directions, lighting conditions, etc.
To overcome these problems, we used the Matlab package WAFO [
45] to generate training and test data in a completely synthetic way. Specifically, we generated several scenarios comprising linear and nonlinear Gaussian waves in an area with a similar extent of the one used in previous WASS setups (see
Table 1 for details).
Each scenario is composed by a sequence of sea surfaces sampled on a regular grid at a frame rate of 7 Hz, simulated using the bimodal (swell+wind) Torsethaugen spectral density model implemented in WAFO. Sea-state parameters are randomized to simulate a wide range of conditions that can be considered reasonable for a typical WASSfast installation on an offshore research platform. All the generated surfaces are the expected outputs of our CNN, divided into training and testing sets. In detail, for training data, we generated 200 different scenarios: for each one, we selected 64 frames, for a total of 12,800 different surfaces (each one with corresponding previous and next frames). The test set includes 100 scenarios, each one including 32 frames, for a total of 3200 surfaces.
To generate the sparse input we designed a specific sampling procedure so that the resulting points exhibit features as close as possible to an actual stereo acquisition.
We opted for a non-uniform sampling of each surface
: we did this by associating each grid point
with a different probability of being observed: we denote such probability as
. All points have the same “initial” probability of being sampled, equal to
. In this way, we ideally obtain a uniform sampling with density
d: we will address to such variable
d in the rest of the paper as the density parameter for data generation. Then, we simulated waves self-occlusion by decreasing with a factor
the probability for a point to be observed only if it exhibits a negative gradient on the
y-direction (In our experiments, we kept a fixed
). Therefore, given a surface
, we define
as follows:
The input image
is then computed sampling surface
according to the outcome of a random variable
following a Bernoulli distribution:
In this way, we obtain a non-uniform sampling that is coherent with the waves direction and the (virtual) stereo cameras capturing the scene.
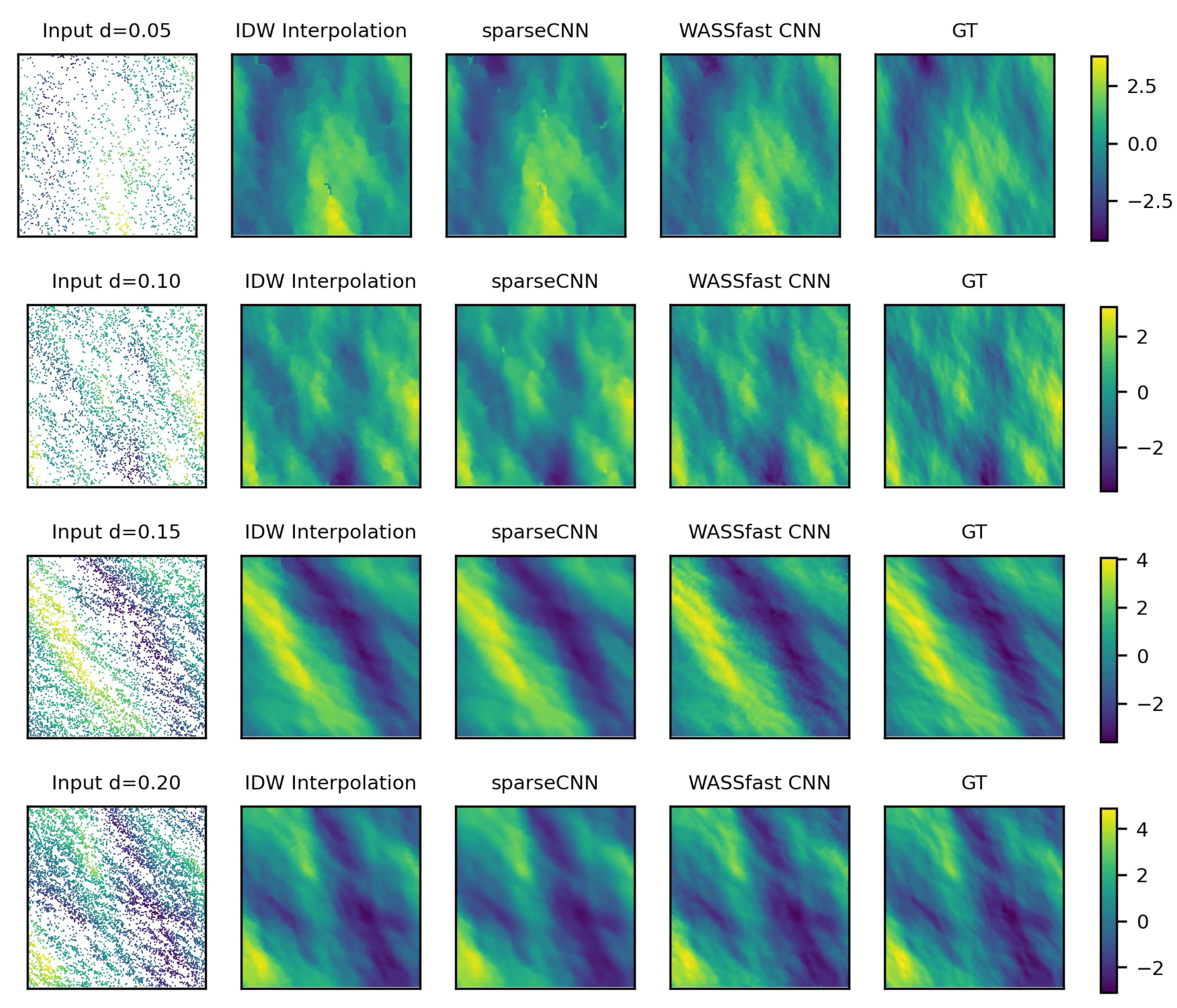
Figure 6 displays the resulting points applying respectively a low sampling ratio (
, left) and a higher one (
, center), together with the Ground Truth surface (GT). Moreover, we introduced random holes, i.e., areas where surface points are completely missing. This aspect is also fundamental for simulating real-world data since the acquired point clouds may exhibit missing data in relatively large areas. To this end, we introduced a parameter
representing the maximum number of holes appearing in a single frame: each image will therefore include a random number of holes in the interval
. Each generated hole is also characterized by a variable size, uniformly selected in the range
and by a variable shape, expressed as a covariance value in the range
.
3.1. Loss Function
As mentioned before, the training process aims at estimating the weights of the neural network model (i.e., the values of convolution kernels and biases) so that the produced output is as similar as possible to the true output . This notion of similarity is given by the so-called Loss Function that gives a penalty factor depending on how much is different from the correct output.
Needless to say that the loss function plays a crucial role to let the network behave as expected. A sophisticated loss function may better account for challenging situations at a price of a more unstable gradient during training phase with the consequent risk of being stuck on a local minima. Several loss functions have been proposed in the literature when working with Neural Networks for image processing [
46]. In the case of our application, we used a combination of L1 loss and Structural Similarity Index (SSIM) proposed by Wang et al. [
47] weighted by a factor
(set to
in all our experiments). The complete loss function used for training is shown in Equation (
8):
3.2. Training Process
As previously discussed, the proposed WASSfast CNN is composed by three main blocks: depth completion, temporal combiner, and surface reconstruction. The depth completion task plays a fundamental role for the surface reconstruction, since its output is directly used in the prediction step of the temporal combiner to merge frames at different times and obtain a denser set of points. Needless to say, the temporal combiner presented in our architecture is effective only if the depth completion block produces a reasonable estimate of the correct underlying surface. When the training process is started, this unlikely happens since the initial weights are randomly generated. Therefore, at an initial training stage, the temporal combiner will “scramble" the phases of completely random surfaces, producing outputs significantly far from the actual surface. This makes the whole optimization highly unstable and hard to converge in practice.
Note that the trainable parts of the network are the initial depth completion block (repeated for input at times and ) and the weights of sparse convolutions involved in the final reconstruction step. Indeed, the depth completion block can be seen as an independent sub-network, producing a dense surface from sparse input points. For this reason, we decided to first train the depth completion block as a standalone network: in this way, we can plug the (very close to optimal) weights in the complete WASSfast CNN network and proceed with global optimization avoiding training instability. Hence, the training process is divided into two steps:
In this way, the depth completion block is optimized beforehand so its initial weights (when the full network train is performed) are already close to the global optimum.
Moreover, while training the depth completion block, we observed that changes in the density of training data have a significant effect on the reconstruction accuracy. We experimentally observed that starting with a relatively high sample density and gradually lowering its value throughout the optimization leads to a quicker and more stable convergence. The concept of presenting to the network gradually complex examples during training is addressed in the literature as
curriculum learning [
48,
49,
50]. In some cases, such a method is shown to be an effective training strategy, leading to fast and stable convergence and to a better network generalization.
We train the depth completion block in groups of several epochs, reducing the sample density range in each group and testing the resulting loss on a separated validation set, according to the following schedule:
50 epochs, sampling
50 epochs, sampling
70 epochs, sampling
70 epochs, sampling
where denotes a uniform distribution over the interval . After that, we filled the pre-trained weights in the depth completion block and trained the full network for 50 more epochs, until the loss shows no significant change between each iteration. For this last step, we restrict the input density d in , since it represents closely the density of real-world data. For the IDW convolution part, we empirically identified a good kernel, namely a matrix with its values set equal to the distance from the window center to the power of . Considering the density of our data, we found this configuration of IDW to be suitable to obtain a smooth initial surface without introducing artifacts.
In both of the training steps, we employed all the surfaces generated in the training set and randomly generated sparse input data with holes as described previously, with and (in pixels). Note that the random generation of the input points takes place at the beginning of each epoch, so the network is constantly feed with new patterns of sparse data, avoiding overfitting. In all cases, we used the the Adam optimizer with an adaptive learning rate, starting from and automatically decreased to a minimum of according to the slope of the loss function during the training.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}